|
|||
SongList-Klasse als Gattung zu entwickeln, die wir aufteilen können in Kataloge und Listen.
SongList-Objektes abspeichern sollen. Wir haben drei offensichtliche Möglichkeiten. Wir benutzen den Ruby-Array-Typ, den Ruby-Hash-Typ
oder wir bauen uns eine eigene Liste zusammen. Weil wir faul sind sehen wir uns erstmal die Arrys und Hashes an und nehmen eines davon für unsere Klasse.
Array enthält eine Liste mit Objekt-Referenzen. Jede Objekt-Referenz besetzt eine Position in dem Array und wird durch eine nicht-negative ganze Zahl identifiziert.
Man kann Arrays erzeugen, indem man Literale benutzt oder indem man explizit ein Array-Objekt erzeugt. Ein literales Array ist einfach eine Liste von Objekten zwischen eckigen Klammern.
a = [ 3.14159, "pie", 99 ] |
||
a.type |
ģ | Array |
a.length |
ģ | 3 |
a[0] |
ģ | 3.14159 |
a[1] |
ģ | "pie" |
a[2] |
ģ | 99 |
a[3] |
ģ | nil |
|
||
b = Array.new |
||
b.type |
ģ | Array |
b.length |
ģ | 0 |
b[0] = "second" |
||
b[1] = "array" |
||
b |
ģ | ["second", "array"] |
[]-Operator.
Wie bei den meisten Ruby-Operatoren ist dies tatsächlich eine Methode (in der Klasse Array) und kann daher auch in Unterklassen überschrieben werden. Wie das Beispiel zeigt, fangen Array-Indizes bei 0 an. Wenn man das Array über eine einzelne Nummer indiziert, gibt es das Objekt an dieser Position zurück oder nil falls da nichts ist. Wenn man ein Array mit einer negativen Nummer indiziert, zählt es von hinten. Dies wird in Figur 4.1 auf Seite 37 gezeigt.
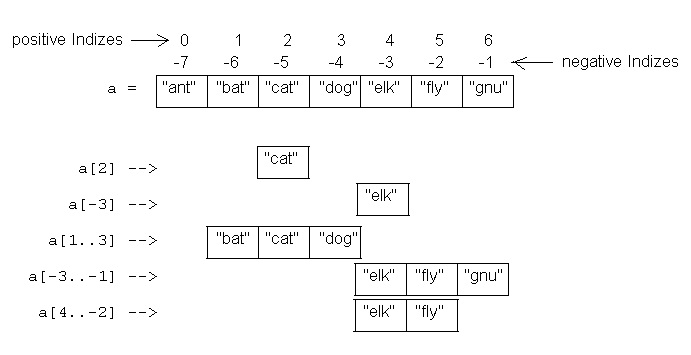 Figur 4.1 Indizieren von Arrays
Figur 4.1 Indizieren von Arraysa = [ 1, 3, 5, 7, 9 ] |
||
a[-1] |
ģ | 9 |
a[-2] |
ģ | 7 |
a[-99] |
ģ | nil |
[start, count]. Dann bekommt man ein neues Array zurück, das aus den count Objekt-Referenzen, angefangen mit Position start, besteht.
a = [ 1, 3, 5, 7, 9 ] |
||
a[1, 3] |
ģ | [3, 5, 7] |
a[3, 1] |
ģ | [7] |
a[-3, 2] |
ģ | [5, 7] |
a = [ 1, 3, 5, 7, 9 ] |
||
a[1..3] |
ģ | [3, 5, 7] |
a[1...3] |
ģ | [3, 5] |
a[3..3] |
ģ | [7] |
a[-3..-1] |
ģ | [5, 7, 9] |
[]-Operator besitzt einen korrespondierenden []=-Operator, der es einem ermöglicht, Elemente in einem Array zu setzen. Wenn man diesen mit einem Einzel-Zahl-Index benutzt, wird das Element an dieser Stelle mit dem überschrieben, was auf der rechten Seite der Zweisung steht. Alle Lücken, die entstehen könnten, werden mit nil gefüllt.
| a = [ 1, 3, 5, 7, 9 ] | ģ | [1, 3, 5, 7, 9] |
| a[1] = 'bat' | ģ | [1, "bat", 5, 7, 9] |
| a[-3] = 'cat' | ģ | [1, "bat", "cat", 7, 9] |
| a[3] = [ 9, 8 ] | ģ | [1, "bat", "cat", [9, 8], 9] |
| a[6] = 99 | ģ | [1, "bat", "cat", [9, 8], 9, nil, 99] |
[]=
aus zwei Zahlen besteht (Start und Länge) oder aus einem Bereich, dann werden alle diese ausgewählten Elemente aus dem ursprünglichen Array ersetzt durch was auch immer auf der rechten Seite der Zuweisung steht. Wenn die Länge Null ist, wird die rechte Seite vor die Startposition eingefügt; keine Elemente werden entfernt. Wenn die rechte Seite selber wieder ein Array ist, werden dessen Elemente zum Ersetzen benutzt. Die Array-Größe wird automatisch angepasst, wenn der Index eine andere Zahl von Elementen bestimmt, als auf der rechten Seite der Zuweisung verfügbar sind.
| a = [ 1, 3, 5, 7, 9 ] | ģ | [1, 3, 5, 7, 9] |
| a[2, 2] = 'cat' | ģ | [1, 3, "cat", 9] |
| a[2, 0] = 'dog' | ģ | [1, 3, "dog", "cat", 9] |
| a[1, 1] = [ 9, 8, 7 ] | ģ | [1, 9, 8, 7, "dog", "cat", 9] |
| a[0..3] = [] | ģ | ["dog", "cat", 9] |
| a[5] = 99 | ģ | ["dog", "cat", 9, nil, nil, 99] |
=> Werte-Paaren zwischen Klammern.
h = { 'dog' => 'canine', 'cat' => 'feline', 'donkey' => 'asinine' } |
||
|
||
h.length |
ģ | 3 |
h['dog'] |
ģ | "canine" |
h['cow'] = 'bovine' |
||
h[12] = 'dodecine' |
||
h['cat'] = 99 |
||
h |
ģ | {"cow"=>"bovine", 12=>"dodecine", "dog"=>"canine", "donkey"=>"asinine", "cat"=>99} |
Hash-Klasse beginnt auf Seite 321.
SongList der Jukebox zu implementieren. Wir werden erstmal eine Liste von Methoden aufstellen, die wir in unserer SongList brauchen. Später werden wir noch Sachen hinzufügen, aber fürs Erste wird dies genügen.
Array realisieren. Außerdem wird die Fähigkeit, einen Song nach seiner als Zahl angegebenen Position zurückzuliefern, von einem Array unterstützt.
Andererseits gibt es da die Forderung, einen Song über den Titel zurückzuliefern, was auf einen Hash hindeutet, mit dem Titel als Schlüssel und dem Song als Wert. Könnten wir einen Hash benutzen? Nun ja, schon, aber es gibt da Probleme. Als Erstes ist ein Hash ungeordnet, wir brauchen also noch einen zusätzlichen Array, um uns die Reihenfolge der Songs zu merken. Ein größeres Problem ist, dass ein Hash nicht mehrere Schlüssel für einen Wert unterstützt. Das wäre ein Problem für unsere Playlist, in der ein Song mehrfach an unterschiedlichen Stellen auftauchen kann. Also nehmen wir erstmal einen Array für die Songs und durchsuchen ihn nach den Titeln, wenn wir das brauchen. Wenn das nachher ein Problem mit der Performance ergibt, können wir immer noch eine hash-basierte Zusatztabelle einführen.
Wir beginnen unsere Klasse mit einer grundlegegenden initialize-Methode, die das Array erzeugt, in dem wir die Songs sichern, und speichern eine Referenz darauf in der Instanz-Variablen @songs.
class SongList def initialize @songs = Array.new end end |
SongList#append-Methode fügt einen gegebenen Song am Ende des @songs Arrays hinzu. Sie gibt self zurück, eine Referenz auf das aktuelle SongList-Objekt. Dies ist eine nützliche Vorgehensweise, denn damit kann man mehrere Aufrufe von append hintereinanderhängen. Wir werden ein Beispiel dafür später noch sehen.
class SongList def append(aSong) @songs.push(aSong) self end end |
deleteFirst- und deleteLast-Methoden hinzu, ganz einfach indem wir
Array#shift bzw.
Array#pop nutzen.
class SongList def deleteFirst @songs.shift end def deleteLast @songs.pop end end |
append das SongList-Objekt zurückgibt, dazu, die Methodenaufrufe aneinanderzuhängen.
list = SongList.new
list.
append(Song.new('title1', 'artist1', 1)).
append(Song.new('title2', 'artist2', 2)).
append(Song.new('title3', 'artist3', 3)).
append(Song.new('title4', 'artist4', 4))
|
nil zurückgegeben wird, wenn die Liste leer geworden ist.
list.deleteFirst |
ģ | Song: title1--artist1 (1) |
list.deleteFirst |
ģ | Song: title2--artist2 (2) |
list.deleteLast |
ģ | Song: title4--artist4 (4) |
list.deleteLast |
ģ | Song: title3--artist3 (3) |
list.deleteLast |
ģ | nil |
[], mit der man auf Elemente über einen Index zugreifen kann. Der Index ist eine Zahl (das prüfen wir mit
Object#kind_of?), wir geben nur das Element an dieser Position zurück.
class SongList def [](key) if key.kind_of?(Integer) @songs[key] else # ... end end end |
list[0] |
ģ | Song: title1--artist1 (1) |
list[2] |
ģ | Song: title3--artist3 (3) |
list[9] |
ģ | nil |
SongList ist, in der Methode
[]
Code zu implementieren, der einen String entgegennimmt und nach einem Song mit diesem Titel sucht. Der Weg scheint klar: wir haben ein Array mit Songs, also gehen wir das einfach Element für Element durch und suchen nach einem Treffer.
class SongList def [](key) if key.kind_of?(Integer) return @songs[key] else for i in 0...@songs.length return @songs[i] if key == @songs[i].name end end return nil end end |
for-Schleife die über ein Array läuft. Was könnte natürlicher sein?
Tatsächlich gibt es etwas, das natürlicher ist. In gewisser Weise ist die for-Schleife ein wenig zu intim mit dem Array; Sie fragt nach der Länge, dann holt sie Werte bis sie einen Treffer findet. Warum sollte man nicht das Array selber darum bitten, einen Test an jedem seiner Mitglieder auszuführen? Genau das ist es, was die find-Methode in Array macht.
class SongList
def [](key)
if key.kind_of?(Integer)
result = @songs[key]
else
result = @songs.find { |aSong| key == aSong.name }
end
return result
end
end
|
if als Anweisung benutzen, um den Code noch kürzer zu kriegen.
class SongList
def [](key)
return @songs[key] if key.kind_of?(Integer)
return @songs.find { |aSong| aSong.name == key }
end
end
|
find ist ein Iterator, der einen Code-Block wiederholt aufruft. Iteratoren und Code-Blöcke gehören zu den interessanteren Merkmalen von Ruby, also werden wir etwas Zeit aufbringen, sie näher zu untersuchen (und dabei werden wir auch genau herausfinden, was diese Zeile Code in unserer []-Methode denn nun wirklich macht).
yield Anweisung. Immer wenn ein yield ausgeführt wird, wird der Code aus dem Block aufgerufen. Wenn der Block wieder verlassen wird, gehts direkt nach dem yield weiter.[Programmiersprachen-Kenner werden erfreut sein zu hören, dass das Schlüselwort yield gewählt wurde, um die yield-Funktion in Liskovs Sprache CLU wiederzuspiegeln, eine Sprache die über 20 Jahre alt ist und immer noch Sachen enthält, auf die die CLU-lose Welt noch wartet.] Fangen wir mit einem einfachen Beispiel an.
def threeTimes
yield
yield
yield
end
threeTimes { puts "Hello" }
|
Hello Hello Hello |
threeTimes. Innerhalb dieser Methode
wird yield drei Mal nacheinander aufgerufen. Jedesmal ruft das den Code im Block auf und eine heitere Begrüßung wird ausgegeben. Was so einen Block allerdings interessant macht ist, dass man Parameter an ihn übergeben und Werte zurückerhalten kann. Als Beispiel schreiben wir eine einfache Funktion, die Mitglieder der Fibonacci-Reihe bis zu einem bestimmten Wert zurückgibt.[Die allgemeine Fibonacci-Reihe ist eine Folge von Zahlen die mit zwei Einsen beginnt. Jede folgende Zahl ist dann die Summe der vorhergehenden beiden Zahlen. Diese Reihe wird manchmal in Sortier-Algorhythmen benutzt oder beim Analysieren von natürlichen Phänomenen.]
def fibUpTo(max)
i1, i2 = 1, 1 # parallele Zuweisung
while i1 <= max
yield i1
i1, i2 = i2, i1+i2
end
end
fibUpTo(1000) { |f| print f, " " }
|
1 1 2 3 5 8 13 21 34 55 89 144 233 377 610 987 |
yield-Anweisung einen Parameter. Dieser Wert wird an den zugehörigen Block weitergegeben. In der Definition des Blockes taucht die Argument-Liste zwischen senkrechten Strichen auf. In dieser Instanz erhält die Variable f den an yield übergebenen Wert, so dass der Block mehrere Mitglieder der Reihe ausgibt. (Diese Beispiel zeigt auch parallele Zuweisungen. Wir kommen darauf auf Seite 77 zurück.) Obwohl es üblich ist, nur einen Wert an einen Block zu übergeben, ist dies nicht notwendig, ein Block kann jede beliebige Anzahl von Argumenten bekommen. Was passiert, wenn der Block eine andere Anzahl von Parametern erwartet, als vom Yield übergeben werden? Durch einen seltsamen Zufall gelten hier die selben Regeln wie bei der parallelen Zuweisung (mit einem kleinen Unterschied: werden mehrere Parameter an einen yield übergeben, so gelten diese als ein Array, falls der Block nur ein Argument erwartet).
Parameter für einen Block können existierende lokale Variablen sein; in diesem Falle bleibt der neue Wert der Variable erhalten, wenn der Block fertig ist. Das kann zu ganz unerwartetem Verhalten führen, aber dafür gibt es einen Performance-Gewinn, wenn man bereits existierende Variablen benutzt.[Mehr Informationen darüber und über andere Fallstricke gibts ab Seite 129, mehr Informationen über die Performance ab Seite 130.]
Ein Block kann auch einen Wert an die Methode zurückgeben. Der Wert des letzten ausgewerteten Ausdrucks dieses Blockes wird an die Methode als Wert von yield zurückgegeben. Genauso funktioniert die find-Methode der Klasse Array. [Die find-Methode wird tatsächlich im Modul Enumerable definiert, die in die Klasse Array eingebunden ist.] Ihre Implementierung würde ungefähr so aussehen.
class Array |
||
def find |
||
for i in 0...size |
||
value = self[i] |
||
return value if yield(value) |
||
end |
||
return nil |
||
end |
||
end |
||
|
||
[1, 3, 5, 7, 9].find {|v| v*v > 30 } |
ģ | 7 |
true liefert, gibt die Methode das dazugehörende Element zurück. Wenn kein Element passt, gibt die Methode nil zurück. Das Beispiel zeigt den Nutzen dieses Verfahrens bei Iteratoren. Die Klasse Array macht, was sie am besten kann, sie greift auf Array-Elemente zu und überlässt es dem Code der Applikation, sich um die speziellen Anforderungen zu kümmern (in diesem Fall das Finden eines Eintrags, der irgendwelchen mathematischen Kriterien genügt).
Einige Iteratoren gibt es bei vielen Aufzählungstypen von Ruby. Wir haben uns schon find angesehen. Zwei andere sind each und
collect.
each ist wahrscheinlich der einfachste Iterator --- das einzige was er macht, ist yield mit nacheinander allen Elementen seiner Aufzählung auszuführen.
[ 1, 3, 5 ].each { |i| puts i }
|
1 3 5 |
each-Iterator hat in Ruby einen besonderen Platz; auf Seite 87 werden wir beschreiben, wie er als Basis für die for-Schleife dient, und ab Seite 104 werden wir sehen, wie man durch die Definition einer each-Methode einen Haufen Funktionalität zu einer eigenen Klasse für lau hinzufügen kann.
Ein anderer gebräuchlicher Iterator ist collect, der jedes Element der Aufzählung nimmt und es an den Block weitergibt. Die vom Block zurückgegebenen Ergebnisse werden zum Erzeugen eines neuen Arrays benutzt. Als Beispiel:
["H", "A", "L"].collect { |x| x.succ } |
ģ | ["I", "B", "M"] |
yield aufruft. Das Teil, das diesen Iterator aufruft ist einfach nur ein mit dieser Methode verbundener Code-Block. Man braucht keine Hilfs-Klasse, die den Iterator-Status enthält, wie in Java oder C++. In dieser wie in vielen anderen Beziehungen ist Ruby eine transparente Sprache.
Wenn man ein Ruby-Programm schreibt, konzentriert man sich auf die anstehende Aufgabe, nicht darauf, Hilfsgerüste zur Unterstützung der Sprache selber zu bauen.
Iteratoren sind nicht auf existierende Daten in Arrays und Hashes begrenzt. Wie wir beim Fibonacci-Beispiel sahen, kann ein Iterator erzeugte Werte zurückgeben. Diese Fähigkeit wird bei den Input/Output-Klassen von Ruby benutzt, die ein Iterator-Interface besitzen, das nacheinander Zeilen (oder Bytes) in einem I/O-Stream zurückliefert.
f = File.open("testfile")
f.each do |line|
print line
end
f.close
|
This is line one This is line two This is line three And so on... |
inject-Funktion benutzen.
sumOfValues "Smalltalk Methode" ^self values inject: 0 into: [ :sum :element | sum + element value] |
inject arbeitet folgendermaßen: Beim ersten Mal wenn der Block aufgerufen wird, wird sum auf den inject-Parameter gesetzt (in diesem Fall Null) und element wird auf das erste Element des Arrays gesetzt. Beim zweiten und allen weiteren Malen wenn der Block aufgerufen wird, wird sum auf den Rückgabewert des Blocks vom vorhergehenden Mal gesetzt. Auf diese Weise wird sum benutzt, um eine fortlaufende Gesamtsumme zu bilden. Der endgültige Wert von inject ist derjenige, der beim letzen Aufruf des Blocks zurükgegeben wurde.
Ruby hat keine inject-Methode, aber man kann einfach eine schreiben. In diesem Fall fügen wir sie zur Array-Klasse hinzu, während wir auf Seite 102 sehen werden, wie man sie auch allgemeiner verfügbar machen kann.
class Array |
||
def inject(n) |
||
each { |value| n = yield(n, value) } |
||
n |
||
end |
||
def sum |
||
inject(0) { |n, value| n + value } |
||
end |
||
def product |
||
inject(1) { |n, value| n * value } |
||
end |
||
end |
||
[ 1, 2, 3, 4, 5 ].sum |
ģ | 15 |
[ 1, 2, 3, 4, 5 ].product |
ģ | 120 |
class File
def File.openAndProcess(*args)
f = File.open(*args)
yield f
f.close()
end
end
File.openAndProcess("testfile", "r") do |aFile|
print while aFile.gets
end
|
This is line one This is line two This is line three And so on... |
openAndProcess-Methode ist eine Klassen-Methode --- sie kann unabhängig von einem speziellen File-Objekt aufgerufen werden. Wir wollen, dass sie die selben Argumente entgegennimmt wie die konventionelle File.open-Methode, aber wir kümmern uns nicht wirklich darum, was das für welche sind. Stattdessen spezifizieren wir diese Argumente als *args, was bedeutet ``sammel die aktuellen an diese Methode übergebenen Parameter in einem Array ein''. Wir rufen dann File.open auf und übergeben *args als Parameter. Dabei wird das Array zurück in einzelne Parameter aufgefächert. Insgesamt werden also bei diesem openAndProcess alle reinkommenden Parameter einfach an File.open weitergegeben.
Wenn die Datei geöffnet wurde, wird von openAndProcess aus yield aufgerufen und das Offene-Datei-Objekt an den Block übergeben. Wenn der Block beendet wird, wird die Datei geschlossen. Auf diese Weise wurde die Verantwortung für das Schließen einer offenen Datei vom Benutzer der Datei-Objekte an diese Objekte selber verschoben.
Schließlich wird in diesem Beispiel noch do...end benutzt, um einen Block zu definieren. Der einzige Unterschied zur Benutzung von Klammern ist die Priorität: do...end bindet schwächer als ``{...}''. Wir werden die Wirkung davon ab Seite 236 noch diskuttieren.
Diese Technik, Dateien ihren eigenen Lebensfaden verwalten zu lassen, ist so nützlich, dass die mit Ruby mitgelieferte Klasse File das direkt unterstützt. Falls File.open einen assoziierten Block dazubekommt, dann wird dieser Block zusammen mit der Datei aufgerufen und die Datei wird geschlossen, sowie der Block beendet wird. Das ist interessant, bedeutet es doch, dass File.open gleich zwei unterschiedliche Verhaltensweisen hat: Falls es mit einem Block zusammen aufgerufen wird, dann führt es den Block aus und schließt die danach Datei. Falls es ohne Block aufgerufen wird, gibt es das Datei-Objekt zurück. Dies wird ermöglicht durch die Methode
Kernel::block_given?, die true zurückgibt, falls ein Block mit der aktuellen Methode assoziiert wird. Damit könnte man File.open (wieder ohne irgendwelches Fehlerhandling) ungefähr so implementieren.
class File def File.myOpen(*args) aFile = File.new(*args) # Falls es einen Block gibt, die Datei übergeben und die # Datei schließen beim Zurückkehren if block_given? yield aFile aFile.close aFile = nil end return aFile end end |
bStart = Button.new("Start")
bPause = Button.new("Pause")
# ...
|
Button-Klasse haben es die Hardware-Leute so gedeichselt, dass eine Callback-Methode, buttonPressed, aufgerufen wird.
Der offensichtliche Weg zum Hinzufügen von Funktionalität zu diesen Buttons ist, Unterklassen von Button zu erzeugen und jeder dieser Unterklassen ihre eigene buttonPressed-Methode mitzugeben.
class StartButton < Button
def initialize
super("Start") # Initialisierung der Buttons aufrufen end
def buttonPressed
# do start actions...
end
end
bStart = StartButton.new
|
Button sich ändert, müssen wir eine Menge an Anpassungen machen. Zum anderen werden die Aktionen, die beim Drücken eines Buttons ausgelöst werden, auf einem ganz falschen Level beschrieben; sie sind nicht das Merkmal eines Buttons, sondern das Merkmal der Jukebox, die diese Buttons benutzt. Wir können dieses Problem lösen durch die Benutzung von Blöcken.
class JukeboxButton < Button
def initialize(label, &action)
super(label)
@action = action
end
def buttonPressed
@action.call(self)
end
end
bStart = JukeboxButton.new("Start") { songList.start }
bPause = JukeboxButton.new("Pause") { songList.pause }
|
JukeboxButton#initialize. Wenn der letzte Parameter in einer Methoden-Definition mit einem Ampersand (wie in &action) anfängt, sucht Ruby jedesmal wenn diese Methode aufgerufen wird nach einem Code-Block. Dieser Code-Block wird zu einem Objekt der Klasse Proc konvertiert und an den Parameter gebunden. Man kann dann diesen Parameter wie jede andere Variable auch benutzen. In unserem Beispiel haben wir ihn an die Instanzvariable @action gebunden.
Wenn die Callback-Methode buttonPressed aufgerufen wird, benutzen wir die
Proc#call-Methode für dieses Objekt, um den Block aufzurufen.
Also was genau haben wir nun, wenn wir ein Proc-Objekt erzeugen? Das interessante daran ist, dass es mehr ist als nur eine Stückchen Code. Mit dem Block verbunden (deswegen ein Proc-Object) bleibt der ganze Kontext, in dem der Block definiert wurde: der Wert von
self und die Methoden, Variablen und Konstanten der Umgebung. Teil des Zaubers von Ruby ist, das dieser Block immer noch all diese originalen Bereichs-Informationsn nutzen kann, selbst wenn die Umgebung, in der er definiert war ansonsten schon verschwunden ist. In anderen Sprachen wird diese Möglichkeit Closure genannt.
Schauen wir uns ein konstruiertes Beispiel an, Diese Beispiel nutzt die Methode
proc, die einen Block zu einem Proc-Objekt konvertiert.
def nTimes(aThing) |
||
return proc { |n| aThing * n } |
||
end |
||
|
||
p1 = nTimes(23) |
||
p1.call(3) |
ģ | 69 |
p1.call(4) |
ģ | 92 |
p2 = nTimes("Hello ") |
||
p2.call(3) |
ģ | "Hello Hello Hello " |
nTimes gibt ein Proc-Objekt zurück, das den Parameter der Methode, nämlich aThing referenziert. Selbst wenn dieser Parameter eigentlich nicht mehr im zugehörigen Bereich ist: wenn der Block aufgerufen wird, bleibt der Parameter für den Block erreichbar.