| Typ | Bedeutung | Siehe Seite | ||||||
%q |
String mit einfachen Anführungszeichen | 204 | ||||||
%Q, % |
String mit doppelten Anführungszeichen | 204 | ||||||
%w |
Array aus Tokens | 206 | ||||||
%r |
Muster eines regulären Ausdrucks | 207 | ||||||
%x |
Shell-Kommando | 220 | ||||||
|
|||
KCODE-Option benutzt werden, wie auf Seite 139
beschrieben.]
Ruby ist eine zeilenorientierte Sprache. Ruby-Ausdrücke und -Anweisungen
werden durch das Zeilenende begrenzt, außer die Anweisung ist offensichtlich
unvollständig --- wenn zum Beispiel das letzte Teil auf einer Zeile ein
Operator oder ein Komma ist. Man kann Semikolons benutzen, um mehrere Ausdrücke
auf eine Zeile zu bekommen. Weiter kann man mit einen Backslash (`\') anzeigen,
dass der Ausdruck auf der nächsten Zeile weitergehen soll. Kommentare fangen mit
einem `#' an und gehen bis zum Zeilenende. Kommentare werden während der
Kompilierung ignoriert.
a = 1 b = 2; c = 3 d = 4 + 5 + # braucht kein '\' 6 + 7 e = 8 + 9 \ + 10 # '\' benötigt |
stdin des Compilers
schicken.
echo 'print "Hello\n"' | ruby |
__END__'' enthält ohne Whitespaces vorne oder hinten dran, dann wird
diese Zeile als Ende des Programms angesehen --- alle folgenden Zeilen werden nicht
mehr compiliert. Allerdings können diese Zeilen in das laufende Programm eingelesen
werden, wenn man das globale IO-Objekt DATA
benutzt, wie auf Seite 219 beschrieben.
BEGIN-Blöcke) und nachdem das Programm
abgeschlossen ist (die END-Blöcke).
BEGIN {
begin code
}
END {
end code
}
|
BEGIN- und END-Blöcke besitzen.
Die BEGIN-Blöcke werden in der Reihenfolge ihres Auftretens abgearbeitet, die
END-Blöcke in der umgedrehten Reihenfolge.
Allgemein begrenzter Input
| |||||||||||||||||||||||||||
('',
``['', ``{'' oder ``<'', dann geht das Literal bis zu
dem passenden schließenden Begrenzer, wobei ins Literal eingebaute
Klammernpaare mitgezählt werden. Bei allen anderen Begrenzern endet das Literal
beim nächsten Auftreten des Begrenzers.
%q/this is a string/ %q-string- %q(a (nested) string) |
%q{def fred(a)
a.each { |i| puts i }
end}
|
Fixnum
oder Bignum.
Fixnum-Objekte enthalten Integers, die so groß sind wie ein Word des
Rechners minus 1 Bit. Immer wenn ein Fixnum-Objekt diesen Bereich
überschreitet, wird es automatisch in ein Bignum-Objekt konvertiert, dessen
Größe nur durch den verfügbaren Speicherplatz begrenzt ist. Wenn eine Operation
auf ein Bignum ein Ergebnis liefert, das in ein Fixnum reinpasst,
dann wird dieses Ergebnis wieder in ein Fixnum gesteckt.
Integers schreibt man mit einem optionalen Vorzeichen, einem optionalen
Indikator für die Basis (0 (das sind Nullen) für oktal, 0x für hexadezimal oder 0b
für binär), gefolgt von einem String mit den zu dieser Basis passenden Ziffern.
Underscores werden in diesem String ignoriert.
Man kann den Integer-Wert eines ASCII-Zeichens erhalten, indem man ein Fragezeichen
vor das Zeichen setzt. Control- und Meta-Kombinationen (auf deutschen Tastaturen sind
das Strg- und Alt-Tasten-Kombinationen) von Buchstaben können gleichfalls
mit ?\C-x, ?\M-x, and ?\M-\C-x erzeugt werden. Man erhält die
Control-Version eines Zeichens ch mit ch & 0x9f und die
Meta-Version mit ch | 0x80. Den Integer-Wert des Backslash bekommt
man mit ?\\.
123456 # Fixnum 123_456 # Fixnum (Underscore wird ignoriert) -543 # Negative Fixnum 123_456_789_123_345_789 # Bignum 0xaabb # Hexadezimal 0377 # Oktal -0b1010 # Binär (negativ) 0b001_001 # Binär ?a # Zeichen-Code ?A # Zeichen-Code des Großbuchstabens ?\C-a # Control-a = A - 0x40 ?\C-A # Großschreibung bei Control wird ignoriert ?\M-a # Meta setzt Bit 7 ?\M-\C-a # Meta- und Control-a |
Float-Objekt umgewandelt, entsprechend dem double-Datentyp
des Rechners. Auf den Dezimalpunkt muss eine Ziffer folgen, sonst versucht
1.e3 die Methode e3 der Klasse Fixnum
aufzurufen.
12.34 |
» | 12.34 |
-.1234e2 |
» | -12.34 |
1234e-2 |
» | 12.34 |
String. Die verschiedenen
Mechanismen unterscheiden sich darin, wie der String abgegrenzt wird und wie viel
Ersetzungen in ihm vorgenommen werden.
String-Literale in einfachen Anführungszeichen ('stuff' und
%q/stuff/) erleben am wenigsten Ersetzungen.
Beide konvertieren die Folge \\ in einen einfachen Backslash. Die Form mit den
einfachen Anführungszeichen konvertiert noch \' in ein einfaches Anführungszeichen.
'hello' |
» | hello |
'a backslash \'\\\'' |
» | a backslash '\' |
%q/simple string/ |
» | simple string |
%q(nesting (really) works) |
» | nesting (really) works |
%q no_blanks_here ; |
» | no_blanks_here |
Ersetzungen bei Strings in doppelten Anführungszeichen
| ||||||||||||||||||||||||||||||||||||||||||||||||||||
a = 123 |
||
"\123mile" |
» | Smile |
"Say \"Hello\"" |
» | Say "Hello" |
%Q!"I said 'nuts'," I said! |
» | "I said 'nuts'," I said |
%Q{Try #{a + 1}, not #{a - 1}} |
» | Try 124, not 122 |
%<Try #{a + 1}, not #{a - 1}> |
» | Try 124, not 122 |
"Try #{a + 1}, not #{a - 1}" |
» | Try 124, not 122 |
a = 123
print <<HIER
Regeln für doppelte \
Anführungszeichen gelten.
Sum = #{a + 1}
HIER
print <<-'DORT'
Einfache Anführungszeichen.
Oben stand auch #{a + 1}
DORT
|
Regeln für doppelte Anführungszeichen gelten.
Sum = 124
Einfache Anführungszeichen
Oben stand auch #{a + 1}
|
String-Objekt zusammengezogen.
'Con' "cat" 'en' "ate" |
» | "Concatenate" |
jcode-Bibliothek einen Satz von Operationen für String, die
mit EUC, SJIS oder UTF-8 Codierung geschrieben wurden. Der darunterliegende String
wird aber immer noch als Folge von Bytes angesprochen.] und jedes Byte
darf jeden der 256 möglichen 8-bit-Werte enthalten, inklusive Null und Newline.
Die Ersetzungsmechanismen aus Tabelle 18.2 auf Seite 205 ermöglichen die passende
und übertragbare Darstellung von nicht-druckbaren Zeichen.
Jedesmal wenn ein literaler String in einer Zuweisung oder als Parameter benutzt
wird, wird ein neues String-Objekt erzeugt.
for i in 1..3 print 'hello'.id, " " end |
537685230 537685200 537685170 |
String beginnt auf Seite 368.
..expr und expr...expr Range-Objekte.
Bei der Zwei-Punkte-Form gehören die Grenzen dazu, bei der Drei-Punkte-Form die
obere Grenze nicht. Details gibts bei der Beschreibung der Klasse Range
auf Seite 364. Für andere Einsätze der Ranges siehe auch die Beschreibung für
Vergleichs-Ausdrücke auf Seite 224.
Array werden erzeugt mit einer durch
Kommas getrennten Folge von Objekt-Referenzen in eckigen Klammern. Ein eventuelles
Komma am Ende dieser Folge wird ignoriert.
arr = [ fred, 10, 3.14, "This is a string", barney("pebbles"), ]
|
%w,
welche durch Leerzeichen getrennte Teile als aufeinander folgende Elemente in ein
Array packt. Dabei kann ein gewolltes Leerzeichen mit einem Backslash escaped werden.
Dies ist eine Form des allgemein begrenzten Inputs, beschrieben auf den Seiten
202 - 203.
arr = %w( fred wilma barney betty great\ gazoo ) |
||
arr |
» | ["fred", "wilma", "barney", "betty", "great gazoo"] |
Hash wird erzeugt mit einer Liste von
Schlüssel/Wert-Paaren in geschweiften Klammern, mit entweder einem Komma oder
=> zwischen Schlüssel und Wert. Ein Komma am Schluss wird ignoriert.
colors = { "red" => 0xf00,
"green" => 0x0f0,
"blue" => 0x00f
}
|
hash mit einem Hash-Wert antworten muss, und der Hash-Wert
zu einem gegebenen Schlüssel darf sich nicht ändern.
Das bedeutet, dass gewisse Klassen (wie etwa Array und
Hash, nach derzeitigem Stand) nicht vernünftig als Schlüssel
benutzt werden können, weil ihr Hash-Wert je nach Inhalt wechseln kann.
Wenn man eine externe Referenz auf ein Objekt hält, das als Schlüssel benutzt wird,
und dann mit dieser Referenz das Objekt tauscht und so den Hash-Wert ändert, dann kann
die Hash-Auswahl über diesen Schlüssel nicht mehr funktionieren.
Weil Strings die gebräuchlichsten Schlüssel von allen sind und die String-Inhalte sich
häufig ändern, werden String-Schlüssel in Ruby speziell behandelt. Wenn man ein String-Objekt
als Hash-Schlüssel benutzt, wird der Hash den String intern kopieren und diese Kopie als
Schlüssel benutzen. Änderungen an dem Original-String haben dann keine Auswirkungen
auf den Hash.
Wenn man eigene Klassen schreibt und Instanzen davon als Hash-Schlüssel benutzt,
solte man sicher gehen, dass entweder (a) die Zuordnungen der Schlüssel-Objekte sich nicht mehr ändern, nachdem sie einmal
erzeugt wurden oder (b) man jedesmal, wenn sie geändert wurde, die Methode
Hash#rehash
aufruft.:Object :myVariable |
Regexp.
Sie können erzeugt werden durch Aufruf des Regexp.new-Konstruktors
oder durch Angeben der literalen Formen /pattern/ und
%r{pattern}. Das %r-Konstrukt ist wieder eine Form des
allgemein begrenzten Inputs (beschrieben auf den Seiten 202 -203).
/pattern/
/pattern/options
%r{pattern}
%r{pattern}options
Regexp.new( 'pattern' [, options] )
|
Regexp-Objekte
benutzt, bestehen die Optionen aus einem oder mehreren Zeichen direkt nach dem Ende-Zeichen.
Wenn man Regexp.new benutzt, dann sind die Optionen Konstanten als zweiter
Parameter des Konstruktors.
i |
Groß/Kleinschreibung egal. Beim Vergleich wird die Groß/Keinschreibung
ignoriert. Das passiert auch, wenn die globale Variable $= gesetzt ist |
o |
Einmal ersetzen. Alle #{...}-Ersetzungen in diesem speziellen
regulären Ausdruck werden nur einmal ausgeführt, beim ersten Aufruf. Sonst werden
die Ersetzungen jedes Mal ausgeführt, wenn das Literal ein Regexp-Objekt
erzeugt. |
m |
Mehrzeilen-Modus. Normalerweise passt ``.'' auf jedes Zeichen außer
Newline. Mit der /m-Option passt ``.'' auf wirklich jedes Zeichen. |
x |
Erweiterter Modus. Komplexe reguläre Ausdrücke können schwierig zu lesen sein. Mit der `x'-Option kann man Leerzeichen, Newlines und Kommentare in das Muster einfügen, um es lesbarer zu machen. |
^$\A\z\Z\b, \B[characters]|, (, ), [, ^, $, * und ?, die sonst eine
spezielle Bedeutung haben, verlieren diese hier.
Die Zeichenfolgen
\nnn, \xnn, \cx, \C-x, \M-x und \M-\C-x
besitzen die Bedeutung wie in Tabelle 18.2 auf Seite 205 angegeben.
Die Folgen \d, \D, \s, \S, \w und \W
sind Abkürzungen für Gruppen von Zeichen, wie in Tabelle 5.1 auf Seite 62 anbegeben.
Die Folge c1-c2
repräsentiert alle Zeichen zwischen c1 und c2, Grenzen inklusive.
Die literalen Zeichen ] oder - müssen direkt nach der öffnenden Klammer
kommen. Ein Aufwärtspfeil (^), der direkt nach der öffnenden Klammer kommt, negiert
den Sinn des Musters, das Muster erfasst dann alle Zeichen, die nicht in der
Zeichenklasse sind.
\d, \s, \w. (Punkt)/m-Option auch Newline).
*+{m,n}?*, + und {m,n} Modifikatoren sind defaultmäßig gierig. Gefolgt von einem
Fragezeichen sind sie es nicht mehr.
|re2| besitzt geringe Priorität.
(...)/abc+/ erfasst einen String mit einem ``a,'' einem ``b''
und einem oder mehreren ``c''s. /(abc)+/ erfasst eine oder mehr Folgen
von ``abc''. Klammern benutzt man auch, um die Ergebenisse des Mustervergleichs
einzusammeln. Für jede öffnende Klammer speichert Ruby das Ergebnis dieses Teiltreffers bis zur
schließenden Klammer als aufzählende Gruppen. Innerhalb des gleichen Musters zeigt
\1 auf den Treffer der ersten Gruppe, \2 auf den der zweiten Gruppe und
so weiter. Außerhalb des Musters dienen die speziellen Variablen
$1, $2und so weiter dem gleichen Zweck.
#{...}/o-Option
nur beim ersten Mal.
\0, \1, \2, ... \9, \&, \`, \', \+(?
und ). Die Klammern dieser Erweiterungen sind auch Gruppen, aber sie
erzeugen keine Rückwärtsreferenzen: sie haben keinen Einfluss auf \1 und
$1 usw.
(?# >Kommentar)(?:re)$1 und so nicht ändern will. In dem folgenden Beispiel erfassen
beide Muster ein Datum mit entweder Doppelpunkten oder Leerzeichen zwischen Monat,
Tag und Jahr. Die erste Form speichert die Trennzeichen in $2 und $4,
die zweite nicht.
date = "12/25/01" |
||
date =~ %r{(\d+)(/|:)(\d+)(/|:)(\d+)} |
||
[$1,$2,$3,$4,$5] |
» | ["12", "/", "25", "/", "01"] |
date =~ %r{(\d+)(?:/|:)(\d+)(?:/|:)(\d+)} |
||
[$1,$2,$3] |
» | ["12", "25", "01"] |
(?=re)$& zu beeinflussen. Im nächstan Beispiel erfasst die scan-Methode
Wörter mit nachfolgendem Komma, ohne dass die Kommas im Ergebnis enthalten sind.
str = "red, white, and blue" |
||
str.scan(/[a-z]+(?=,)/) |
» | ["red", "white"] |
(?!re)/hot(?!dog)(\w+)/ jedes Wort, das
die Buchstaben ``hot'' enthält, an denen kein ``dog'' hängt. Zurück geliefert wird das
Ende des Wortes in $1.
(?>re)/a.*b.*a/ exponetiell viel Zeit, wenn es auf einen String angewandt wird, der
ein ``a'' enthält, gefolgt von mehreren ``b''s, aber ohne abschließendem ``a''. Dies kann vermieden
werden, wenn man einen verschachtelten regulären Ausdruck benutzt /a(?>.*b).*a/.
Bei dieser Form verbraucht der innere Ausdruck den ganzen Input-String bis hin zum
letzten ``b''. Wenn dann auf das abschließende ``a'' geprüft wird, besteht keine Notwendigkeit mehr für
eine Rekursion, und der Vergleich ist sofort beendet.
require "benchmark"
include Benchmark
str = "a" + ("b" * 5000)
bm(8) do |test|
test.report("Normal:") { str =~ /a.*b.*a/ }
test.report("Nested:") { str =~ /a(?>.*b).*a/ }
end
|
user system total real Normal: 2.620000 0.000000 2.620000 ( 2.651591) Nested: 0.000000 0.000000 0.000000 ( 0.000883) |
(?imx)(?-imx)(?imx:re)(?-imx:re)Reservierte Wörter
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
fred anObject _x three_two_one |
@'') gefolgt
von einem Groß- oder Kleinbuchstaben, optional gefolgt von Namen-Zeichen.
@name @_ @Size |
@@'') gefolgt
von einem Groß- oder Kleinbuchstaben, optional gefolgt von Namen-Zeichen.
@@name @@_ @@Size |
module Math PI = 3.1415926 end class BigBlob |
$'') gefolgt von Namen-Zeichen. Zusätzlich gibt es noch
zwei-Zeichen-Variablen, deren zweites Zeichen ein Interpunktions-Zeichen ist. Diese
vordefinierten Variablen werden ab Seite 216 aufgelistet. Schließlich kann man eine
globale Variable erschaffen mit ``$-'' gefolgt von jedem einzelnen Zeichen.
$params $PROGRAM $! $_ $-a $-. |
def a print "Function 'a' called\n" 99 end for i in 1..2 if i == 2 print "a=", a, "\n" else a = 1 print "a=", a, "\n" end end |
a=1 Function 'a' called a=99 |
a = 1 if false; a |
MY_CONST = 1 MY_CONST = 2 # generates a warning |
prog.rb:2: warning: already initialized constant MY_CONST |
MY_CONST = "Tim" |
||
MY_CONST[0] = "J" # alter string referenced by constant |
||
MY_CONST |
» | "Jim" |
::'' benutzen,
mit einem Ausdruck, der das Klassen- oder Modul-Objekt zurückliefert, vorne dran. Konstanten, die
außerhalb jeder Klasse oder Moduls definiert wurden, kann man ohne Zusätze oder mit
dem Bereichsoperator ``::'' ohne Vorsatz ansprechen. Konstanten dürfen nicht in Methoden
definiert werden.
OUTER_CONST = 99 |
||
class Const |
||
def getConst |
||
CONST |
||
end |
||
CONST = OUTER_CONST + 1 |
||
end |
||
Const.new.getConst |
» | 100 |
Const::CONST |
» | 100 |
::OUTER_CONST |
» | 99 |
nil.
Klassen-Variablen sind in der gesamten Klasse oder im Modul-Rumpf verfügbar. Eine
Klassen-Variable muss vor der Benutzung initialisiert werden. Eine Klassen-Variable
wird von allen Instanzen einer Klasse gemeinsam benutzt.
class Song @@count = 0 def initialize @@count += 1 end def Song.getCount @@count end end |
Object definiert und verhalten sich wie globale Variablen. Klassen-Variablen
in Singleton-Methoden gehören zu dem Empfänger, wenn dieser eine Klasse oder Modul ist; ansonsten gehören sie
zu der Klasse des Empfängers.
class Holder @@var = 99 def Holder.var=(val) @@var = val end end a = Holder.new def a.var @@var end |
Holder.var = 123 |
||
a.var |
» | 123 |
nil. Jede Instanz einer Klasse besitzt einen eigenen Satz von Instanz-Variablen.
Instanz-Variablen sind in Klassen-Methoden nicht verfügbar.
Lokale Variablen sind insofern einzigartig, dass ihr Gültigkeitsbereich statisch
festgelegt wird, auch wenn ihre Existenz erst dynamisch hervorgerufen wird.
Eine lokale Variable wird erst dann dynamisch erzeugt, wenn ihr das erste Mal während des Programmablaufs ein
Wert zugewiesen wird. Auf der anderen Seite wird der Gültigkeitsbereich einer
lokalen Variable statisch festgelegt: der unmittelbar umschließende Block, Methodendefinition,
Klassendefinition, Moduldefinition oder das top-level Programm. Wenn man eine Variable
referenziert, die zwar im Gültigkeitsbereich existiert aber der noch nichts zugewiesen wurde, erhält man
eine NameError-Exception.
Lokale Variablen mit dem selben Namen sind unterschiedliche Variablen, wenn sie in
unterschiedlichen Gültigkeitsbereichen auftauchen.
Methoden-Parameter werden als zu dieser Methode lokale Variablen angesehen.
Block-Parametern wird ihr Wert zugewiesen, wenn der Block aufgerufen wird.
a = [ 1, 2, 3 ]
a.each { |i| puts i } # i local to block
a.each { |$i| puts $i } # assigns to global $i
a.each { [email protected]| puts @i } # assigns to instance variable @i
a.each { |I| puts I } # generates warning assigning to constant
a.each { |b.meth| } # invokes meth= in object b
sum = 0
var = nil
a.each { |var| sum += var } # uses sum and var from enclosing scope
|
while-, until- und for-Schleifen gehören zum
Gültigkeitsbereich, der sie umgibt; vorher schon existierende Variablen können in der
Schleife benutzt werden und neu erzeugte Variablen sind hinterher außerhalb der Schleifen verfügbar.
true zu ändern (außer man ist ein Politiker). Einträge mit {}
sind thread local.
Viele globale Variablen sehen aus wie die Flüche von Snoopy: $_,
$!, $& und so weiter. Das hat historische Gründe, weil die
meisten dieser Variablen-Namen aus Perl stammen. Wem das Merken all dieser seltsamen
Zeichen schwer fällt, sollte sich die Bibliotheks-Datei ``English'' auf Seite ??? ansehen, die
den gebräuchlichsten globalen Variablen eher beschreibende Namen gibt.
In den folgenden Tabellen von Variablen und Konstanten zeigen wir den Variablen-Namen,
den Typ des referenzierten Objekts und eine Beschreibung.
| $! | Exception | Das Exception-Objekt, das an raise übergeben wurde.
{} |
| $@ | Array | Der von der letzten Exception erzeugte Stack-Backtrace.
Siehe Kernel#caller
auf Seite 417. {} |
$=) werden nach einem erfolglosen Mustervergleich
auf nil gesetzt.
| $& | String | Der vom letzten erfolgreichen Mustervergleich erfasste String. Diese Variable ist lokal zum aktuellen Gültigkeitsbereich. {} |
| $+ | String | Der Inhalt der vom letzten erfolgreichen Mustervergleich
erfassten Gruppe. So wird $+ bei "cat" =~/(c|a)(t|z)/ auf ``t'' gesetzt.
Diese Variable ist lokal zum aktuellen Gültigkeitsbereich. {} |
| $` | String | Der String, der direkt vor dem vom letzten erfolgreichen Mustervergleich erfassten String steht. Diese Variable ist lokal zum aktuellen Gültigkeitsbereich. {} |
| $' | String | Der String, der direkt nach dem vom letzten erfolgreichen Mustervergleich erfassten String steht. Diese Variable ist lokal zum aktuellen Gültigkeitsbereich. {} |
| $= | Object | Falls auf einen Wert ungleich nil oder
false gesetzt, so werden alle Mustervergleiche
ohne Berücksichtigung der Groß-klein-Schreibung durchgeführt,
String Vergleiche genauso und bei Hash-Werten als String ebenso. |
| $1 to $9 | String | Der Inhalt der vom letzten erfolgreichen Mustervergleich
erfassten Gruppen. So wird $1 bei "cat" =~/(c|a)(t|z)/ auf ``a'' gesetzt und
$2 auf ``t''.
Diese Variable ist lokal zum aktuellen Gültigkeitsbereich.
{} |
| $~ | MatchData | Ein Objekt, das die Ergebnisse eines erfolgreichen
Mustervergleichs enthält. Die Variablen $&,
$`, $' und $1 bis $9 werden alle aus
$~ abgeleitet. Zuweisungen an $~
ändern den Wert dieser abgeleiteten Variablen.
Diese Variable ist lokal zum aktuellen Gültigkeitsbereich.
{} |
| $/ | String | der Input-Record-Separator (defaultmäßig Newline).
Mit diesem Wert bestimmen Routinen wie
Kernel#gets
die Grenzen innerhalb von Aufzählungen.
Falls auf nilgesetzt liest gets die ganze Datei. |
| $-0 | String | Synonym für $/. |
| $\ | String | Dieser String wird an den Output jedes Aufrufs von Methoden wie
Kernel#print und
IO#write gehängt. Defaultmäßig auf
nilgesetzt. |
| $, | String | Der Trennungs-String, der zwischen die Parameter von
Methoden wie Kernel#print und
Array#join gesetzt wird.
Defaultmäßig nil, also kein Text. |
| $. | Fixnum | Die Nummer der letzten von der aktuellen Input-Datei gelesenen Zeile. |
| $; | String | Das Trennmuster für String#split.
Kann von der Kommmandozeile aus mit dem
-F-Flag gesetzt werden. |
| $< | Object | Dieses Objekt ermöglicht den Zugriff auf die hintereinander
gehängten Dateien, die als Kommandozeilen-Argumente mitgeliefert wurden, oder $stdin
(falls es keine Argumente gab). $< unterstützt ähnliche Methoden wie ein
File object:
binmode, close,
closed?, each,
each_byte, each_line,
eof, eof?, file,
filename, fileno,
getc, gets, lineno,
lineno=, pos, pos=,
read, readchar,
readline, readlines,
rewind, seek, skip,
tell, to_a, to_i,
to_io, to_s genauso wie Methoden aus
Enumerable. Die Methode file
liefert ein File-Objekt für die aktuell gelesene
Datei. Dieses kann sich ändern, während $< sich durch die
Dateien aus der Kommandozeile liest. {} |
| $> | IO | Das Ziel des Outputs für Kernel#print
und Kernel#printf.
Defaultwert ist $stdout. |
| $_ | String | Die letzte von Kernel#gets oder
Kernel#readline gelesene Zeile.
Viele string-bezogene Funktionen im KernelModul arbeiten
defaultmäßig mit $_. Die Variable ist lokal zum aktuellen Gültigkeitsbereich.
{} |
| $defout | IO | Synonym für $>. |
| $-F | String | Synonym für $;. |
| $stderr | IO | Der aktuelle Standard-Error-Kanal. |
| $stdin | IO | Der aktuelle Standard-Input-Kanal. |
| $stdout | IO | Der aktuelle Standard-Output-Kanal. |
| $0 | String | Der Name des gerade ausgeführten top-level Ruby-Programms.
Üblicherweise der Dateiname des Programms. Auf einigen Systemen ändert eine Zuweisung an
diese Variable den Namen des Prozesses, der (zum Beispiel) vom ps(1)-Kommando
geliefert wird. |
| $* | Array | Ein Array mit Strings, die die Kommandozeilen-Optionen vom Aufruf des Programms enthalten. Die Optionen für den Rupy-Interpreter sind aber schon entfernt. {} |
| $" | Array | Ein Array mit Dateinamen für Module, die von
require geladen wurden.
{} |
| $$ | Fixnum | Die Prozessnummer des ausgeführten Programms. {} |
| $? | Fixnum | Der Exit-Status des letzten terminierten Kind-Prozesses. {} |
| $: | Array | Ein Array mit Strings, wobei jeder String ein Verzeichnis
mit Ruby-Skripten und binären Erweiterungen bezeichnet, das von den load- und
require-Methoden durchsucht wird.
Der Anfangswert ist der mit der -I-Kommandozeilen-Option
übergebene Wert, gefolgt von der bei der Installation definierten
Standard-Bibliothek und gefolgt vom aktuellen Verzeichnis (``.'').
Mit dieser Variablen kann man aus einem Programm heraus den
Default-Suchpfad ändern; üblicherweise benutzten Programme
$: << dir, um dir an den Pfad
anzuhängen. {} |
| $-a | Object | True, falls die -a-Option in
der Kommandozeile angegeben wurde. {} |
| $-d | Object | Synonym für $DEBUG. |
| $DEBUG | Object | Wird auf true gesetzt, falls die
-d-Kommandozeilen-Option angegeben wurde. |
| __FILE__ | String | Der Name der aktuellen Quell-Datei. {} |
| $F | Array | Das Array mit der aufgesplitteten Input-Zeile, falls
die -a-Kommandozeilen-Option benutzt wurde. |
| $FILENAME | String | Der Name der aktuellen Input-Datei.
Äquivalent zu $<.filename. {} |
| $-i | String | Falls der Einfüge-Modus fürs Editieren eingeschaltet
ist (vielleicht mit der
-i-Kommandozeilen-Option), dann enthält
$-i die Erweiterung, die beim Erzeugen einer Bakup-Datei
benutzt wird. Das Schreiben eines Wertes in $-i schaltet den Einfüge-Modus
ein. Siehe Seite 138. |
| $-I | Array | Synonym für $:. {} |
| $-K | String | Aktiviert das Mehr-Byte Code-System für Strings und
reguläre Ausdrücke. Äquivalent zur
-K-Kommandozeilen-Option. Siehe Seite 139.
|
| $-l | Object | Wird auf true gesetzt, wenn die -l-Option
(die die Zeilen-Ende-Verarbeitung aktiviert)
in der Kommandozeile enthalten ist. Siehe Seite 139. {} |
| __LINE__ | String | Die aktuelle Zeilennummer im Quelltext. {} |
| $LOAD_PATH | Array | Ein Synonym für $:. {} |
| $-p | Object | Wird auf true gesetzt, falls die -p-Option
(die eine implizite while gets ...
end-Schleife um dein Programm setzt) in der Kommandozeile
enthalten ist. Siehe Seite 139. {} |
| $SAFE | Fixnum | Der aktuelle Sicherheits-Level (siehe Seite 258). Der Wert dieser Variablen darf durch Zuweisung niemals verringert werden. {} |
| $VERBOSE | Object | Wird auf true gesetzt, falls die -v,
--version oder
-w-Option in der Kommandozeile angegeben ist. Das Setzen
dieser Option auf true veranlasst den Interpreter und
einige Bibliotheks-Routinen, zusätzliche Informationen zu melden. |
| $-v | Object | Synonym für $VERBOSE. |
| $-w | Object | Synonym für $VERBOSE. |
| ARGF | Object | Ein Synonym für $<. |
| ARGV | Array | Ein Synonym für $*. |
| ENV | Object | Ein hash-ähnliches Objekt, das die Umgebungsvariablen
des Programms enthält. Eine Instanz der Klasse Object,
ENV besitzt den vollen Satz an Hash-Methoden. Man
benutzt es, um den Wert einer Umgebungsvariablen abzufragen oder zu setzen, wie in
ENV["PATH"] und ENV['term']="ansi". |
| false | FalseClass | Singleton-Instanz der Klasse FalseClass. {} |
| nil | NilClass | Die Singleton-Instanz der Klasse NilClass.
Der Wert von uninitialisierten Instanzen und globalen Variablen. {} |
| self | Object | Der Empfänger (Object) der aktuellen Methode. {} |
| true | TrueClass | Singleton-Instanz der Klasse TrueClass. {} |
| DATA | IO | Wenn die Datei des Hauptprogramms die Direktive
__END__enthält, dann wird die Konstante DATA so initialisiert, dass sie
beim Lesen die Zeilen liefert, die auf __END__ folgen. |
| FALSE | FalseClass | Synonym für false. |
| NIL | NilClass | Synonym für nil. |
| RUBY_PLATFORM | String | Die Kennung der Plattform, auf der dieses Programm läuft. Dieser String hat die selbe Form wie die Plattformkennung, die vom GNU-Configure-Programm benutzt wird (was ja auch kein Zufall ist). |
| RUBY_RELEASE_DATE | String | Das Datum dieses Releases. |
| RUBY_VERSION | String | Die Versionsnummer des Interpreters. |
| STDERR | IO | Der aktuelle Standard-Error-Kanal für dieses Programm. Der
Anfangswert für $stderr. |
| STDIN | IO | Der aktuelle Standard-Input-Kanal für dieses Programm. Der
Anfangswert für $stdin. |
| STDOUT | IO | Der aktuelle Standard-Output-Kanal für dieses Programm. Der
Anfangswert für $stdout. |
| TOPLEVEL_BINDING | Binding | Ein Binding-Objekt, das die Bindung auf Rubys
Top-Level repräsentiert --- das Level, auf dem Programme anfänglich ausgeführt werden. |
| TRUE | TrueClass | Synonym für true. |
%x am Anfang.
Der Wert dieses Strings ist der Standard-Output des Kommandos, ausgeführt auf der
Standard-Shell des Betriebssystems. Die Ausführung besetzt auch die $?-Variable
mit dem Rückgabewert des Kommandos.
filter = "*.c"
files = `ls #{filter}`
files = %x{ls #{filter}}
|
Symbol-Objekt wird erzeugt durch
das Voranstellen eines Doppelpunkts vor einen Operator, Variable, Konstante, Methode,
Klasse oder Modul.
Das Symbol-Objekt ist einmalig für jeden unterschiedlichen Namen, aber referenziert nicht
auf die spezielle Instanz des Namens, so ist etwa das Symbol für:fred immer das
gleiche, egal in welchem Kontext. Ein Symbol ist wie ein Atom in anderen hoch-leveligen
Sprachen.
::'').
barney # Variablen-Referenz APP_NAMR # Konstanten-Referenz Math::PI # genau bestimmte Konstanten-Referenz |
Ruby-Operatoren (nach Priorität geordnet)
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
a, b, c = 1, "cat", [ 3, 4, 5 ] |
anObj = A.new
anObj.value = "hello" # äquivalent zu anObj.value=("hello")
|
[]='') im Empfänger auf und übergibt als Parameter alle
Indize, die in den Klammern stehen, gefolgt vom rvalue.
Dies wird in Tabelle 18.5 auf Seite 222 gezeigt.
Zuordnung von Element-Referenz zu Methoden-Aufruf
| |||||||||||||||||
Array, dann wird der rvalue ersetzt durch die Elemente
des Arrays, wobei jedes Element wieder einen eigenen rvalue ergibt.
Array konvertiert, dieses wird in einen Satz von
rvalues expandiert wie unter (1) beschrieben.
a,b=b,a die Werte
in ``a'' und ``b'' austauscht.
nil zugewiesen.
begin body end |
begin und end zusammengefasst werden. Der Wert
dieses Block-Ausdrucks ist der letzte innerhalb des Blocks berechnete Wert.
Block-Ausdrücke spielen auch im Exception-Handling eine Rolle, das wird ab Seite 237 beschrieben.
false und nil.
Beide Werte werden in einem boolschen Kontext wie falsch behandelt. Alle anderen Werte werden
wie wahr behandelt.
and- und der &&-Operator wertet den ersten Operanden aus.
Falls er falsch ist, gibt der Ausdruck falsch zurück; sonst gibt der Asudruck den
Wert des zweiten Operators zurück.
expr1 and expr2expr1 && expr2 |
or- und der ||-Operator wertet der ersten Operanden aus.
Falls er wahr ist, gibt der Ausdruck wahr zurück; sonst gibt der Ausdruck den Wert
des zweiten Operators zurück.
expr1 or expr2expr1 || expr2 |
not- und der !-Operator werten seinen Ausdruck aus.
Falls er wahr ist, gibt der Ausdruck wahr zurück. Falls er falsch ist, gibt der Ausdruck falsch zurück.
Die ausgeschriebenen Formen dieser Operatoren (and, or und not) besitzen
eine geringere Priorität als die entsprechenden Symbol-Formen (&&,
|| und !). Siehe auch Tabelle 18.4 auf Seite 221.
Der defined?-Operator gibt nil zurück, wenn sein Argument, das frei wählbar ist, nicht
definiert ist. Sonst gibt er eine Beschreibung dieses Arguments zurück. Beispiele gibts auf
Seite 80 in der Anleitung.
==, ===,
<=>, <, <=, >, >=, =~ sowie die
Standard-Methoden eql? und equal? definiert (siehe Tabelle 7.1 auf Seite 81). All diese
Operatoren sind als Methoden implementiert.
Obwohl diese Operatoren intuitiv zu erfassen sind, bleibt es doch der implementiernden
Klasse überlassen, sie mit vernünftiger Bedeutung zu füllen. (Der Übersetzer: So ist ist es zum Beispiel
völliger Unsinn, ein > für komplexe Zahlen zu definieren!) Die Bibliotheks-Referenz
beginnt auf Seite 279 und beschreibt die Bedeutung der Vergleiche für die eingebauten Klassen.
Das Modul Comparable bietet Unterstützung beim Implementieren
der Operatoren ==,
<, <=, >, >= und der Methode between?
in Hinblick auf <=>.
Der Operator === wird in case-Ausdrücken benutzt, beschrieben auf Seite 225.
Sowohl == als auch =~ besitzen negierte Formen , != und
!~. Diese werden von Ruby während der Syntax-Analyse konvertiert:
a!=b wird abgebildet auf !(a==b) und a!~b wird abgebildet auf
!(a =~b). Für
!= and !~ gibt es keine entsprechenden Methoden!
if expr1 .. expr2 while expr1 ... expr2 |
true zurück, falls er im gesetzten Status ist,
sonst false.
Die Zwei-Punkte-Form verhält sich leicht anders als die Drei-Punkte-Form. Wenn die
Zwei-Punkte-Form zum ersten Mal den Übergang von ungesetzt nach gesetzt vollzieht,
wertet sie direkt die End-Bedingung aus und macht den Übergang dem entsprechend. Das
heißt, wenn bei einem Aufruf sowohl expr1 und
expr2 wahr sind, dann beendet die Zwei-Punkte-Form den Aufruf im ungesetzten Zustand.
Trotzdem gibt sie bei diesem Aufruf noch true zurück.
Der Unterschied ist im folgenden Code ersichtlich:
a = (11..20).collect {|i| (i%4 == 0)..(i%3 == 0) ? i : nil} |
||
a |
» | [nil, 12, nil, nil, nil, 16, 17, 18, nil, 20] |
|
||
a = (11..20).collect {|i| (i%4 == 0)...(i%3 == 0) ? i : nil} |
||
a |
» | [nil, 12, 13, 14, 15, 16, 17, 18, nil, 20] |
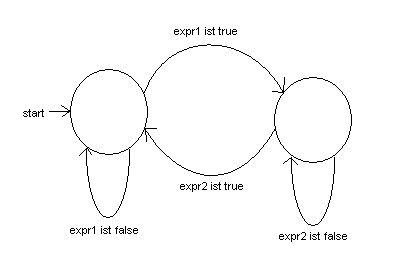 Figur 18.1 Zustandsänderungen bei boolschen Bereichen
Figur 18.1 Zustandsänderungen bei boolschen Bereichen$_ verglichen.
if /re/ ... |
if $_ =~ /re/ ... |
if boolean-expression[then]body elsif boolean-expression[then]body else body end |
unless boolean-expression[then]body else body end |
then trennt den Rumpf von der Bedingung. Es wird nicht
benötigt, falls der Rumpf auf einer neuen Zeile beginnt. Der Wert eines
if- oder unless-Ausdrucks ist der Wert des letzten ausgewerteten Ausdrucks,
egal in welchem Rumpf.
expression if boolean-expressionexpression unless boolean-expression |
true ist (bzw. false ist bei unless).
boolean-expression ? expr1 : expr2 |
case target
when [comparison]+[then]body
when [comparison]+[then]body
...
[ else
body]
end
|
=== target
ausführt.
Wenn ein Vergleich wahr ergibt, wird die Suche gestoppt und der entsprechende Rumpf wird ausgeführt.
case gibt dann den Wert des letzten ausgeführten Ausdrucks zurück. Falls
kein Vergleicher (comparison) passt, wird der Else-Zweig ausgeführt, wenn keiner vorhanden ist,
gibt case einfach nur nil zurück.
Das Schlüsselwort then trennt den when-Vergleicher vom Rumpf und
wird nicht benötigt, wenn der Rumpf auf einer neuen zeile anfängt.
while boolean-expression[do]body end |
until boolean-expression[do]body end |
do das boolean-expression vom
body und kann weggelassen werden, falls der Rumpf body auf einer neuen
Zeile beginnt.
for [name]+ in expression[do]body end |
for-Schleife wird ausgeführt, als wäre sie die folgende
each-Schleife, außer dass die im for-Rumpf definierten Variablen
auch außerhalb der Schleife verfügbar sind, die in einem Iterator definierten sind
das nicht.
expression.each do | [name]+ | body end |
loop,
das über seinen dazugehörenden Block iteriert, ist kein Sprachkonstrukt --- es ist
eine Methode des Moduls Kernel.
expression while boolean-expressionexpression until boolean-expression |
begin/end-Block,
dann wird expression null oder mehrere Male ausgeführt, solange wie boolean-expression true ist (false ist bei until).
Falls expression ein begin/end-Block ist, wird der Block immer
mindestens ein Mal ausgeführt.
break, redo, next, and
retry ändern den normalen Ablauf in einer while, until,
for oder über Iterator kontrollierten Schleife.
break beendet die umschließende Schliefe direkt --- die Ausführung geht
direkt hinter dem Block weiter. redo wiederholt die Schleife von Anfang
an, aber ohne die Bedingung neu zu prüfen oder das nächste Element (bei einem Iterator) zu holen.
next springt ans Ende der Schleife ind macht mit dem nächsten Element der
Iteration weiter.
retry wiederholt die Schleife mit einer neuen Auswertung der Bedingung.
def defname[( [arg[=val]]*[, *vararg][, &blockarg] )]body end |
|
?''), einem Ausrufezeichen
(``!'') oder einem Gleichheitszeichen (``='') enden. Das Gleichheitszeichen ist zwar
auch nur Teil des Namens, bedeutet aber zusätzlich, dass diese Methode ein Attribute-Setter ist
(beschrieben auf Seite 25).
Eine Methodendefinition mit Hilfe eines simplen Methoden-Namens erzeugt man innerhalb einer Klasses oder
eines Moduls eine Instanz-Methode. Eine Instanz-Methode kann man nur aktivieren,
indem man ihren Namen an eine Instanz der definierenden Klasse schickt (oder einer
der Sub-Klassen).
Außerhalb einer Klassen- oder Modul-Definition ergibt ergibt die Definition mit einem
reinen Methoden-Namen eine private Methode der Klasse Object und kann daher
in jedem Kontext ohne Angabe eines Empfängers aufgerufen werden.
Eine Definition über einen Methoden-Namen der Form expr.methodname
erzeugt einer Methode, die an das durch expr gekennzeichnete Objekt
gebunden ist; Diese Methode kann man nur über dieses Objekt aufrufen. In anderen Ruby-Dokumentationen werden diese
Methoden Singleton-Methoden genannt.
class MyClass def MyClass.method # Definition end end |
MyClass.method # Aufruf anObject = Object.new def anObject.method # Definition end anObject.method # Aufruf def (1.class).fred # Empfänger darf ein Ausdruck sein end Fixnum.fred # Aufruf |
begin/end-Block insofern,
dass er Anweisungen zum Exception-Handling enthalten darf (rescue, else und ensure).
def options(a=99, b=a+1) |
||
[ a, b ] |
||
end |
||
options |
» | [99, 100] |
options 1 |
» | [1, 2] |
options 2, 4 |
» | [2, 4] |
Array. Falls im Aufruf nach den regulären Argumenten noch
weitere Argumente folgen, werden diese in diesem frisch erzeugten Array gesammelt.
def varargs(a, *b) |
||
[ a, b ] |
||
end |
||
varargs 1 |
» | [1, []] |
varargs 1, 2 |
» | [1, [2]] |
varargs 1, 2, 3 |
» | [1, [2, 3]] |
def mixed(a, b=99, *c) |
||
[ a, b, c] |
||
end |
||
mixed 1 |
» | [1, 99, []] |
mixed 1, 2 |
» | [1, 2, []] |
mixed 1, 2, 3 |
» | [1, 2, [3]] |
mixed 1, 2, 3, 4 |
» | [1, 2, [3, 4]] |
Proc konvertiert und diesem
Block-Argument zugeordnet. Falls kein Block da ist, wird das Argument auf nil gesetzt.
|
=> Werte-Paaren folgen. Diese
Paare werden in einem einzelnen neuen Hash-Objekt zusammengefasst und
der Methode als einzelner Parameter übergeben.
Danach darf ein einzelner Parameter mit einem vorangestellten Sternchen folgen.
Wenn dieser Parameter ein Array ist, ersetzt Ruby damit ein oder mehrere Parameter.
def regular(a, b, *c) # .. end regular 1, 2, 3, 4 regular(1, 2, 3, 4) regular(1, *[2, 3, 4]) |
Proc-
oder Method-Objekt verweist.
Egal ob ein Block-Argument vorhanden ist oder nicht sorgt Ruby dafür, dass die globale Funktion
Kernel::block_given?
die Verfügbarkeit eines mit dem Aufruf verbundenen Blocks anzeigt.
aProc = proc { 99 }
anArray = [ 98, 97, 96 ]
def block
yield
end
block { }
block do
end
block(&aProc)
def all(a, b, c, *d, &e)
puts "a = #{a}"
puts "b = #{b}"
puts "c = #{c}"
puts "d = #{d}"
puts "block = #{yield(e)}"
end
all('test', 1 => 'cat', 2 => 'dog', *anArray, &aProc)
|
a = test
b = {1=>"cat", 2=>"dog"}
c = 98
d = [97, 96]
block = 99
|
self vorausgesetzt.
Der Empfänger sucht in seiner eigenen Klasse nach der Methoden-Definition und dann nacheinander
in seinen Vorgänger-Klassen. Die Instanz-Methoden von eingebundenen Modulen funktionieren dabei,
als wären sie in einer anonymen Über-Klasse der Klasse, in der sie eingebunden werden. Wenn die
Methode nicht gefunden wird, ruft Ruby die Methode method_missing des
Empfängers auf. Das Standard-Verhalten, definiert in
Kernel::method_missing, ist
dann die Meldung eines Fehlers gefolgt vom Programmabbruch.
Wenn ein Empfänger explizit bei einem Methodenaufruf angegeben ist, darf er vom
Methoden-Namen entweder durch einen Punkt ``.'' oder zwei Doppelpunkte ``::'' getrennt sein.
Der einzige Unterschied zwischen diesen beiden Formen fällt auf, wenn der
Methoden-Name mit einem Großbuchstaben anfängt. In diesem Fall nimmt Ruby an, dass ein
receiver::Thing-Methoden-Aufruf tatsächlich der Versuch ist, auf eine Konstante
mit Namen Thing zuzugreifen außer es gibt noch eine geklammerte Parameterliste
nach dem Methoden-Namen.
Foo.Bar() # Methoden-Aufruf Foo.Bar # Methoden-Aufruf Foo::Bar() # Methoden-Aufruf Foo::Bar # Zugriff auf Konstante |
return [expr]* |
return-Ausdruck beendet die Methode sofort. Der Wert von return ist
nil, wenn kein Parameter angegeben wurde,
der Wert dieses Parameters, wenn einer angegeben wurde, oder ein Array mit allen Parametern, wenn
mehrere angegeben wurden.
super [ ( [param]*[*array] ) ][block] |
super so,
als wäre die original-Methode aufgerufen worden, Allerdings startet die Suche nach dem Methoden-Rumpf
in der Über-Klasse des Objekts, das die Original-Methode enthält. Falls keine
Parameter (und auch keine Klammern) angegeben wurden, bekommt dieser
super-Aufruf die selben Parameter wie die Original-Methode mit, ansonsten die angegebenen.
expr1 operatoroperator expr1expr1 operator expr2 |
(expr1).operator(expr2) |
receiver.attrname = rvalue |
receiver [expr]+receiver [expr]+ = rvalue |
[] des Empfängers
auf und übergibt ihm als Parameter die Ausdrücke in Klammern.
Als Lvalue ruft die Element-Referenz die Methode []= des Empfängers
auf und übergibt ihm als Parameter die Ausdrücke in Klammern, gefolgt von dem
zugehörigen rvalue.
alias neuerNamealterName |
$&, $', $' und $+) verweist.
Lokale Variablen, Instanz-Variablen, Klassen-Variablen und Konstanten dürfen nicht
mit Alias neu verwiesen werden. Die Parameter für alias dürfen Namen oder
Symbole sein.
class Fixnum |
||
alias plus + |
||
end |
||
1.plus(3) |
» | 4 |
|
||
alias $prematch $` |
||
"string" =~ /i/ |
» | 3 |
$prematch |
» | "str" |
|
||
alias :cmd :` |
||
cmd "date" |
» | "Sun Mar 4 23:24:32 CST 2001\n" |
def meth |
||
"original method" |
||
end |
||
|
||
alias original meth |
||
|
||
def meth |
||
"new and improved" |
||
end |
||
meth |
» | "new and improved" |
original |
» | "original method" |
class classname[< superexpr]body end class << anObjectbody end |
Class durch Ausführung des Codes in body.
Bei der ersten Form wird eine benamte Klasse erzeugt oder erweitert. Das resultierende
Class-Objekt wird einer globalen Konstante namens classname
zugewiesen. Der Name sollte mit einem Großbuchstaben anfangen.
Bei der zweiten Form wird eine anonyme (Singleton-) Klasse diesem speziellen
Objekt zugewiesen.
Falls vorhanden so sollte superexpr ein Ausdruck sein, der auf ein
Class-Objekt verweist, das dann als Superklasse der definierten Klasse dient.
Falls er fehlt, wird standardmäßig die Klasse Object verwendet.
Innerhalb von body werden die meisten Ruby-Ausdrücke einfach so ausgewertet, wie sie da stehen.
Allerdings:
::'' zugegriffen werden.
module NameSpace class Example CONST = 123 end end obj = NameSpace::Example.new a = NameSpace::Example::CONST |
Module#include-Methode fügt
die angegebenen Module als anonyme Superklassen zur definierenden Klasse hinzu.
attr oder
include) sind tatsächlich einfache private Instanz-Methoden der Klasse
Module (Dokumentiert ab Seite 348).
Kapitel 19 ab Seite 241 beschreibt genauer, wie
Class-Objekte mit dem Rest der Umgebung interagieren.
obj = classexpr.new [ ( [args]* ) ] |
Class definiert die Instanz-Methode
Class#new, und
initialize in dem frisch erzeugten
Objekt auf und übergibt ihm alle Argumente, die ursprünglich an new übergeben
wurden.
new überschreibt ohne dabei
super aufzurufen, so werden keine Objekte dieser Klasse erzeugt.
Module die
automatisch Zugriffs-Methoden erzeugen.
class name attr attribute[, writable] attr_reader [attribute]+ attr_writer [attribute]+ attr_accessor [attribute]+ end |
module namebody end |
Module-Objekt wird in einer Konstanten gespeichert. Ein Modul darf
Klassen- und Instanz-Methoden enthalten und Konstanten und Klassen-Variablen definieren. Wie bei
Klassen werden Modul-Methoden über das
Module-Objekt als Empfänger aufgerufen und auf Konstanten wird über den
Bereichs-Operator ``::'' zugegriffen.
module Mod CONST = 1 def Mod.method1 # module method CONST + 1 end end |
Mod::CONST |
» | 1 |
Mod.method1 |
» | 2 |
class|module name include expr end |
include-Methode kann man ein Modul innerhalb der Definition
eines andern Moduls oder einer anderen Klasse einbinden. Die Modul- oder Klassen-Definition mit einem
solchen include erhält Zugriff auf die Konstanten, Klassen-Variablen und
Instanz-Methoden des eingebundenen Moduls.
Wenn ein Modul innerhalb einer Klassen-Definition eingebunden wird, so werden
die Konstanten, Klassen-Variablen und Instanz-Methoden dieses Moduls gewissermaßen in einer anonymen (und
unzugänglichen) Super-Klasse dieser Klasse zusammengefasst. Im Speziellen werden Objekte
dieser Klasse auf Nachrichten für die Instanz-Methoden dieses Moduls reagieren.
Ein Modul kann auch auf dem Top-Level eingebunden werden, in diesem Fall werden die
Konstanten, Klassen-Variablen und Instanz-Methoden auf dem Top-Level verfügbar.
include ganz nützlich ist, um Mixin-Funktionalität zur Verfügung zu stellen,
bietet es auch die Möglichkeit, Konstanten, Klassen-Variablen und Instanz-Methoden in einen
anderen Namensraum zu verfrachten. Allerdings ist die in einer Instanz-Methode definierte Funktionalität
nicht als Modul-Methode verfügbar.
module Math def sin(x) # end end # Zugriff auf Math.sin nur über ... include Math sin(1) |
Module#module_function
löst dieses Problem, indem sie eine oder mehrere Instanz-Methoden eines Moduls nimmt und ihre Definitionen
in korrespondierende Modul-Methoden kopiert.
module Math def sin(x) # end module_function :sin end Math.sin(1) include Math sin(1) |
module_function kopiert,
es wird keinesfalls ein einfacher alias-Verweis erzeugt.
self als Empfänger). Deshalb können private Methoden nur in der
definierenden Klase und von direkten Nachkommen innerhalb des selben Objekts aufgerufen werden.
private [aSymbol]* protected [aSymbol]* public [aSymbol]* |
do/end-Paar.
Der Block darf mit einer Argumentliste zwischen senkrechten Strichen beginnen. Ein Code-Block darf nur unmittelbar nach
einem Methoden-Aufruf auftauchen. Der Anfang des Blocks muss auf der selben logischen Zeile
beginnen auf der der Methoden-Aufruf aufhört.
invocation do | a1, a2, ... |
end
invocation { | a1, a2, ... |
}
|
do besizt niedrige Priorität.
Falls der Methoden-Aufruf Parameter besitzt, die nicht in Klammern eingeschlossen sind, so gehört
der Block mit den geschweiften Klammern zum letzten dieser Parameter, nicht zu dem Aufruf.
Der Block mit do gehört dagegen zum Aufruf.
Innerhalb des Rumpfes der aufgerufenen Methode kann der Code-Block mittels der
yield-Methode aufgerufen werden. Wenn man an yield
Parameter gibt, so werden sie an den Block weitergegeben nach den Regeln der parallelen Zuweisung,
beschreiben ab Seite 222.
Der Rückgabewert von yield ist der Wert des letzten innerhalb des Blocks
ausgewerteten Ausdrucks.
Ein Code-Block merkt sich die Umgebung, in der er definiert wurde, und er benutzt bei
jedem Aufruf diese Umgebung.
Proc.new
und
Kernel#proc
in Objekte der Klasse Proc konvertiert oder, indem man sie einer Methode als
Block-Argument mitgibt.
Der Proc-Konstruktor nimmt einen zugeordneten Block und verpackt ihn
zusammen mit genügend Kontext, um dessen Umgebung wieder erstellen zu können, wenn der Block später
aufgerufen wird. Mit der Proc#call-Instanz-Methode
kann man den ursprünglichen Block aufrufen und optional noch Parameter mitgeben. Der Code im Block (und im dazu gehörenden Closure) bleibt während der gesamten Lebensspanne des Proc-Objekts
verfügbar.
Wenn das letzte Argument in der Argument-Liste einer Methode mit einem
Ampersand (``&'') anfängt, so wird jeder Block, der mit der Methode verbunden ist,
in ein Proc-Objekt konvertiert und diesem Parameter zugewiesen.
Exception und seiner Nachfahren
(eine komplette Liste der eingebauten Exceptions liefert Figur 22.1 auf Seite 303).
Kernel::raise-Methode
löst eine Exception aus.
raise raise aString raise thing[, aString[aStackTrace]] |
$! oder löst einen
RuntimeError aus, wenn $! nil ist.
Die zweite Form erzeugt eine neue RuntimeError-Exception und setzt deren
Meldung auf den mitgegebenen String.
Die dritte Form löst eine Exception aus, indem sie die Methode
exception ihres ersten Arguments ausführt. Sie setzt dann die Meldung dieser
Exception und zieht sich auf das zweite und dritte Argument zurück.
Die Klasse Exception und Objekte der Klasse Exception
enthalten eingebaute Methoden mit Namen exception, so dass man den Namen oder die Instanz
einer Exception-Klasse als ersten Parameter für raise benutzen kann.
Wenn eine Exception ausgelöst wird, setzt Ruby eine Referenz auf das
Exception-Objekt in die globale Variable $!.
begin/end-Blocks abhandeln.
begin
code...code...[rescue [parm]*[=> var][then]error handling code...]*[else
no exception code...][ensure
always executed code...]
end
|
rescue-Klauseln besitzen und jede davon darf null oder
mehrere Parameter haben. Eine rescue-Klausel ohne Parameter wird behandelt, als hätte sie
den Parameter
StandardError.
Wenn eine Exception ausgelöst wird, hangelt sich Ruby den Aufruf-Stack entlang, bis es einen
umschließenden begin/end-Block findet. Ruby vergleicht dann bei jeder rescue-Klausel
in diesem Block deren Parameter mit der ausgelösten Exception; jeder Parameter wird mit
$!.kind_of?(parameter) abgeprüft. Wenn die ausgelöste Exception auf einen
rescue-Parameter passt, führt Ruby den Rumpf dieses rescue aus und sucht
danach nicht mehr weiter. Wenn die passende rescue-Klausel mit einem => und einem
Variablen-Namen aufhört, wrid die Variable auf $! gesetzt.
Obwohl die Parameter für die rescue-Klauseln üblicherweise Namen von
Exception-Klassen sind, können sie tatsächlich alle möglichen
Ausdrücke sein (auch Methoden-Aufrufe), die eine passende Klasse zurückliefern.
Falls keine rescue-Klausel auf die augelöste Exception passt, hangelt sich Ruby am
Stack-Frame weiter und sucht nach einem passenden höher-leveligen begin/end-Block.
Falls das bis zum Top-Level so weitergeht, ohne dass ein passendes rescue gefunden wurde, wird das
Programm mit einer Fehlermeldung beendet.
Wenn eine else-Klausel vorhanden ist, wird ihr Rumpf ausgeführt, falls
keine Exception im ursprünglichen Code ausgelöst wurde. Exceptions, die während der
Ausführung der else-Klausel auftreten, werden nicht von der rescue-Klausel aus dem
selben Block wie else abgefangen.
Wenn eine ensure-Klausel vorhanden ist, wird ihr Rumpf immer ausgeführt, bevor der Block
verlassen wird (auch falls eine nicht abgefangene Exception danach weitergereicht wird).
retry-Anweisung kann man innerhalb einer rescue-Klausel benutzen,
um den umschließenden begin/end von Anfang an zu wiederholen.
Kernel::catch
führt den dazugehörenden Block aus.
catch ( aSymbol | aString ) do block... end |
Kernel::throw
unterbricht den normalen Ablauf der Anweisungen.
throw( aSymbol | aString[, anObject] ) |
throw ausgeführt wird, sucht Ruby den Aufruf-Stack nach dem ersten
catch-Block mit passendem Symbol oder String ab. Wenn es einen findet, wird die Suche beendet und die
Ausführung wird nach dem Beenden des catch-Blocks wiederaufgenommen. Ruby beachtet dabei die
ensure-Klauseln aller Block-Ausdrücke, die es bei der Suche nach einem passenden catch durchläuft.
Falls kein passender catch-Block gefunden wird, löst Ruby eine
NameError-Exception an der Stelle des throw aus.