| Einpacken von C Datentypen |
|---|
| VALUEĀ |
Data_Wrap_Struct(VALUE class, void (*mark)(),
void (*free)(), void *ptr")
|
| Ā |
Packt den gegebenen C-Datentyp ptr ein, registriert die
beiden Garbage-Collection-Routinen (siehe unten), und gibt einen VALUE-Zeiger auf
das neue Ruby-Objekt zurück.
Der C-Typ des resultierenden Objekts lautet T_DATA und seine Ruby-Klasse
ist class.
|
| VALUEĀ |
Data_Make_Struct(VALUE class, c-type,
void (*mark)(), void (*free)(), c-type *")
|
| Ā |
Allokiert zuerst eine Struktur des angegebenen Typs, und macht danach weiter
wie Data_Wrap_Struct. c-type ist der Name des C-Datentyps, den wir
einpacken, nicht eine Variable dieses Typs.
|
| Ā |
Data_Get_Struct(VALUE obj,c-type,c-type *")
|
| Ā |
Liefert den ursprünglichen Zeiger. Dieses Makro stellt eine
typsichere Version des Makros DATA_PTR(obj) dar, das den
Zeiger auswertet.
|
#include "ruby.h"
#include "cdjukebox.h"
VALUE cCDPlayer;
static void cd_free(void *p) {
CDPlayerDispose(p);
}
static void progress(CDJukebox *rec, int percent)
{
if (rb_block_given_p()) {
if (percent > 100) percent = 100;
if (percent < 0) percent = 0;
rb_yield(INT2FIX(percent));
}
}
static VALUE
cd_seek(VALUE self, VALUE disc, VALUE track)
{
CDJukebox *ptr;
Data_Get_Struct(self, CDJukebox, ptr);
CDPlayerSeek(ptr,
NUM2INT(disc),
NUM2INT(track),
progress);
return Qnil;
}
static VALUE
cd_seekTime(VALUE self)
{
double tm;
CDJukebox *ptr;
Data_Get_Struct(self, CDJukebox, ptr);
tm = CDPlayerAvgSeekTime(ptr);
return rb_float_new(tm);
}
static VALUE
cd_unit(VALUE self)
{
return rb_iv_get(self, "@unit");
}
static VALUE
cd_init(VALUE self, VALUE unit)
{
rb_iv_set(self, "@unit", unit);
return self;
}
VALUE cd_new(VALUE class, VALUE unit)
{
VALUE argv[1];
CDJukebox *ptr = CDPlayerNew(NUM2INT(unit));
VALUE tdata = Data_Wrap_Struct(class, 0, cd_free, ptr);
argv[0] = unit;
rb_obj_call_init(tdata, 1, argv);
return tdata;
}
void Init_CDJukebox() {
cCDPlayer = rb_define_class("CDPlayer", rb_cObject);
rb_define_singleton_method(cCDPlayer, "new", cd_new, 1);
rb_define_method(cCDPlayer, "initialize", cd_init, 1);
rb_define_method(cCDPlayer, "seek", cd_seek, 2);
rb_define_method(cCDPlayer, "seekTime", cd_seekTime, 0);
rb_define_method(cCDPlayer, "unit", cd_unit, 0);
}
|
| Definieren von Objekten |
|---|
| VALUEĀ |
rb_define_class(char *name, VALUE superclass")
|
| Ā |
Definiert eine neue Klasse auf oberstem Level mit dem angegebenen Namen
name sowie der Oberklasse superclass.
(Für die Klasse Object benutzt man rb_cObject).
|
| VALUEĀ |
rb_define_module(char *name")
|
| Ā |
Definiert ein neues Modul auf oberstem Level mit dem angegebenen Namen name.
|
| VALUEĀ |
rb_define_class_under(VALUE under, char *name,
VALUE superclass")
|
| Ā |
Definiert eine eingebettete Klasse unterhalb der Klasse oder des Moduls under.
|
| VALUEĀ |
rb_define_module_under(VALUE under, char *name")
|
| Ā |
Definiert ein eingebettetes Modul unterhalb der Klasse oder des Moduls under.
|
| voidĀ |
rb_include_module(VALUE parent, VALUE module")
|
| Ā |
Fügt das angegebenene Modul module in die Klasse oder das Modul
parent ein.
|
| voidĀ |
rb_extend_object(VALUE obj, VALUE module")
|
| Ā |
Erweitert das Objekt obj durch das Modul module.
|
| VALUEĀ |
rb_require(const char *name")
|
| Ā |
Gleichbedeutend mit ``require name.''
Liefert Qtrue oder Qfalse zurück.
|
| Definition von Methoden |
|---|
| voidĀ |
rb_define_method(VALUE classmod, char *name,
VALUE(*func)(), int argc")
|
| Ā |
Definiert eine Instanzmethode namens name in der Klasse oder dem Modul classmod,
die durch die C-Funktion func implementiert wird, welche argc Argumente erwartet.
|
| voidĀ |
rb_define_module_function(VALUE classmod, char *name,
VALUE(*func)(), int argc)")
|
| Ā |
Definiert eine Methode namens name in der Klasse classmod,
implementiert durch die C-Funktion func, die argc Argumente erwartet.
|
| voidĀ |
rb_define_global_function(char *name, VALUE(*func)(),
int argc")
|
| Ā |
Definiert eine globale Funktion (eine private Methode von Kernel)
mit Namen name, die durch die C-Funktion func implementiert wird und die
argc Argumente erwartet.
|
| voidĀ |
rb_define_singleton_method(VALUE classmod, char *name,
VALUE(*func)(), int argc")
|
| Ā |
Definiert eine Singleton-Methode in der Klasse classmod mit dem
angegeben Namen name, implementiert durch die C-Funktion func,
die argc Argumente erwartet.
|
| intĀ |
rb_scan_args(int argcount, VALUE *argv, char *fmt, ...")
|
| Ā |
Durchläuft die Argumentliste und weist das Ergebnis Variablen zu ähnlich wie scanf:
fmt ist eine Zeichenkette bestehend aus Null, einem oder zwei Ziffern gefolgt von
einigen Spezifikationsbuchstaben.
Die erste Ziffer gibt die Anzahl der unbedingt nötigen Argumente an; die zweite
ist die Anzahl optionaler Argumente.
Das Zeichen ``*'' bedeutet, dass der Rest der Argumente in ein Ruby-Feld gepackt werden soll.
Ein ``&'' heißt, dass ein angehängter Code-Block übernommen und der angegebenen Variablen
zugewiesen wird (Wurde kein Code-Block angegeben, wird Qnil zugewiesen).
Nach dem fmt-String werden (genau wie bei scanf) Zeiger auf VALUE
erwartet, denen dann die Argumente zugewiesen werden.
VALUE name, one, two, rest;
rb_scan_args(argc, argv, "12", &name, &one, &two);
rb_scan_args(argc, argv, "1*", &name, &rest);
|
|
| voidĀ |
rb_undef_method(VALUE classmod, const char *name")
|
| Ā |
Löscht die angegebene Methode name aus der angegebenen Klasse oder dem Modul classmod.
|
| voidĀ |
rb_define_alias(VALUE classmod, const char *newname,
const char *oldname")
|
| Ā |
Definiert einen Alias für oldname in der Klasse oder dem Modul classmod.
|
| Definition von Variablen und Konstanten |
|---|
| voidĀ |
rb_define_const(VALUE classmod, char *name, VALUE value")
|
| Ā |
Definiert eine Konstante namens name mit dem Wert value
in der Klasse oder dem Modul classmod.
|
| voidĀ |
rb_define_global_const(char *name, VALUE value")
|
| Ā |
Definiert eine globale Konstante namens name mit dem Wert value.
|
| voidĀ |
rb_define_variable(const char *name, VALUE *object")
|
| Ā |
Exportiert die Adresse des in C erzeugten angegeben Objektes object in den
Ruby-Namensraum als name.
Aus Rubysicht ist es eine globale Variable, folglich sollte der Namen name
mit einem führenden Dollar-Zeichen beginnen.
Stellen Sie sicher, dass sie Ruby's Regeln für gültige Variablennamen berücksichtigen;
Variablen mit illegalem Namen sind von Ruby aus nicht ansprechbar.
|
| voidĀ |
rb_define_class_variable(VALUE class, const char *name,
VALUE val")
|
| Ā |
Definiert eine Klassenvariable namens name
(die ein ``@@'' Prefix enthalten muss) in der angegeben Klasse
class und initialisiert sie mit dem Wert value.
|
| voidĀ |
rb_define_virtual_variable(const char *name,
VALUE(*getter)(), void(*setter)()")
|
| Ā |
Exportiert eine virtuelle Variable in den Ruby-Namensraum als globale Variable
$name. Es existiert kein Speicherplatz für diese Variable.
Versuche, sie zu lesen bzw. schreiben rufen die angegebenen Funktionen
mit den folgenden Prototypen auf:
VALUE getter(ID id, VALUE *data,
struct global_entry *entry);
void setter(VALUE value, ID id, VALUE *data,
struct global_entry *entry);
|
Wahrscheinlich werden Sie den entry-Parameter nicht benötigen und
können ihn problemlos in ihren Funktionsdeklarationen auslassen.
|
| voidĀ |
rb_define_hooked_variable(const char *name,
VALUE *variable, VALUE(*getter)(), void(*setter)()")
|
| Ā |
Definiert Funktionen, die aufgerufen werden, wenn eine Variable variable
gelesen oder geschrieben wird.
Siehe auch rb_define_virtual_variable.
|
| voidĀ |
rb_define_readonly_variable(const char *name,
VALUE *value")
|
| Ā |
Genau wie rb_define_variable, aber die Variable ist von Ruby aus nur lesbar.
|
| voidĀ |
rb_define_attr(VALUE variable, const char *name,
int read, int write")
|
| Ā |
Erzeugt Zugriffsmethoden für die angegebene Variable variable, mit Namen
name. Wenn read ungleich null ist, erzeuge eine Lesemethode;
Wenn write ungleich null ist, erzeuge eine Schreibmethode.
|
| voidĀ |
rb_global_variable(VALUE *obj")
|
| Ā |
Registriert die angegebene Adresse beim Garbage-Collector. |
| Aufruf von Methoden |
|---|
| VALUEĀ |
rb_funcall(VALUE recv, ID id, int argc, ...")
|
| Ā |
Ruft die Methode auf, die durch id gegeben ist im
Objekt recv mit der angegebenen Variablenanzahl argc und
den spezifizierten Argumenten (möglicherweise auch gar keinem).
|
| VALUEĀ |
rb_funcall2(VALUE recv, ID id, int argc, VALUE *args")
|
| Ā |
Ruft die Methode auf, die durch id gegeben ist im
Objekt recv mit der angegebenen Variablenanzahl argc und
den Argumenten im C Feld args.
|
| VALUEĀ |
rb_funcall3(VALUE recv, ID id, int argc, VALUE *args")
|
| Ā |
Wie rb_funcall2, ruft aber keine privaten Methoden auf.
|
| VALUEĀ |
rb_apply(VALUE recv, ID name, int argc, VALUE args")
|
| Ā |
Ruft die Methode auf, die durch id gegeben ist im
Objekt recv mit der angegebenen Variablenanzahl argc und
den Argumenten im Ruby Arrayargs.
|
| IDĀ |
rb_intern(char *name")
|
| Ā |
Liefert die ID zu einem gegebenen Namen name.
Wenn der Namen nicht existiert wird ein Eintrag in der Symboltabelle für ihn erzeugt.
|
| char *Ā |
rb_id2name(ID id")
|
| Ā |
Liefert den Namen zu einer gegebenen id.
|
| VALUEĀ |
rb_call_super(int argc, VALUE *args")
|
| Ā |
Ruft die aktuelle Methode in der Oberklasse des aktuellen Objekts auf.
|
| Exceptions (Ausnahmen) |
|---|
| voidĀ |
rb_raise(VALUE exception, const char *fmt, ...")
|
| Ā |
Wirft eine Ausnahmebedingung exception.
Die angegebene Zeichenkette fmt sowie die übrigen
Argumente werden genauso interpretiert wie bei printf.
|
| voidĀ |
rb_fatal(const char *fmt, ...")
|
| Ā |
Wirft eine Fatal-Ausnahme, die den Prozess beendet.
Es werden keine rescue- aber ensure-Blöcke abgearbeitet.
Die angegebene Zeichenkette fmt sowie die übrigen
Argumente werden genauso interpretiert wie bei printf.
|
| voidĀ |
rb_bug(const char *fmt, ...")
|
| Ā |
Beendet den Prozess sofort---es werden keinerlei Behandlungsroutinen aufgerufen.
Die angegebene Zeichenkette fmt sowie die übrigen
Argumente werden genauso interpretiert wie von printf.
Sie sollten diese Funktion nur dann aufrufen, wenn ein fataler Fehler entdeckt wurde.
Sie schreiben aber keine Programme mit fatalen Fehlern, oder doch?
|
| voidĀ |
rb_sys_fail(const char *msg")
|
| Ā |
Wirft eine plattform-spezifische Ausnahmebedingung, die zum letzten
bekannten Systemfehler gehört, zusammen mit der Meldung msg.
|
| VALUEĀ |
rb_rescue(VALUE (*body)(), VALUE args,
VALUE(*rescue)(), VALUE rargs")
|
| Ā |
Führt den Block body mit den Argumenten args aus. Wenn eine
StandardError-Ausnahme auftritt,
führe auch den Block rescue mit den Argumenten rargs aus.
|
| VALUEĀ |
rb_ensure(VALUE(*body)(), VALUE args,
VALUE(*ensure)(), VALUE eargs")
|
| Ā |
Ruft den Block body mit den Argumenten args aus.
Egal, ob eine Ausnahme auftritt oder nicht, führe immer den ensure Block mit den
Argumenten rargs aus, sobald body beendet ist.
|
| VALUEĀ |
rb_protect(VALUE (*body)(), VALUE args,
int *result")
|
| Ā |
Ruft den Block body mit den Argumenten args auf
und liefert etwas ungleich Null im Ergebnis result, wenn dabei irgendeine
Ausnahme auftrat.
|
| voidĀ |
rb_notimplement(")
|
| Ā |
Wirft eine NotImpError-Ausnahme um anzuzeigen, dass die
eingeschlossene Funktion noch nicht implementiert oder auf dieser Plattform nicht
verfügbar ist.
|
| voidĀ |
rb_exit(int status")
|
| Ā |
Beendet Ruby mit dem Status status. Wirft eine SystemExit-Ausnahme und ruft alle registrierten exit Funktionen sowie finalize-Funktionen auf.
|
| voidĀ |
rb_warn(const char *fmt, ...")
|
| Ā |
Produziert (immer) eine Warnmeldung auf dem Standardfehlerausgang.
Die Zeichenkette fmt sowie die übrigen Argumente werden wie bei printf
interpretiert.
|
| voidĀ |
rb_warning(const char *fmt, ...")
|
| Ā |
Produziert nur dann eine eine Warnmeldung auf dem Standardfehlerausgang,
wenn Ruby mit dem -w flag aufgerufen wurde.
Die Zeichenkette fmt sowie die übrigen Argumente werden wie bei printf
interpretiert.
|
| Iteratoren |
|---|
| voidĀ |
rb_iter_break(")
|
| Ā |
Springt aus dem umgebenden Iterator-Block heraus.
|
| VALUEĀ |
rb_each(VALUE obj")
|
| Ā |
Ruft die each Methode für das Objekt obj auf.
|
| VALUEĀ |
rb_yield(VALUE arg")
|
| Ā |
Übergibt die Ausführung an den Iterator-Block im momentanen
Kontext und übergibt das Argumente arg an ihn.
Mehrere Werte können als Feld übergeben werden.
|
| intĀ |
rb_block_given_p(")
|
| Ā |
Liefert true (wahr) wenn yield einen Block im momentanen Kontext
ausführen würde---d.h., wenn ein Code-Block an die aktuelle Methode
übergeben wurde und seine Ausführung möglich ist.
|
| VALUEĀ |
rb_iterate(VALUE (*method)(), VALUE args,
VALUE (*block)(), VALUE arg2")
|
| Ā |
Ruft die Methode method mit den Argumenten args und dem Block
block auf. Ein yield aus dieser Methode ruft
block mit den Argumenten args und einem weiteren Argument arg2 auf.
|
| VALUEĀ |
rb_catch(const char *tag, VALUE (*proc)(), VALUE value")
|
| Ā |
Gleichbedeutend mit Ruby's catch.
|
| voidĀ |
rb_throw(const char *tag , VALUE value")
|
| Ā |
Äquivalent zu Ruby's throw.
|
| Zugang zu Variablen |
|---|
| VALUEĀ |
rb_iv_get(VALUE obj, char *name")
|
| Ā |
Liefert die Instanz-Variable namens name (der mit
einem ``@''-Prefix beginnen muss) des Objekts obj.
|
| VALUEĀ |
rb_ivar_get(VALUE obj, ID name")
|
| Ā |
Liefert die Instanz-Variable name des Objekts obj.
|
| VALUEĀ |
rb_iv_set(VALUE obj, char *name, VALUE value")
|
| Ā |
Setzt den Wert der Instanz-Variablen namens name (der mit einem
``@''-Prefix beginnen muss) im Objekt obj auf value, der
auch zurückgeliefert wird.
|
| VALUEĀ |
rb_ivar_set(VALUE obj, ID name, VALUE value")
|
| Ā |
Setzt den Wert der Instanz-Variablen namens name (der mit einem
``@''-Prefix beginnen muss) im Objekt obj auf value, der
auch zurückgeliefert wird.
|
| VALUEĀ |
rb_gv_set(const char *name, VALUE value")
|
| Ā |
Setzt die globale Variable namens name (das ``$''-Prefix ist
optional) auf value. Liefert value zurück.
|
| VALUEĀ |
rb_gv_get(const char *name")
|
| Ā |
Liefert den Wert der globalen Variable name (das ``$''-Prefix ist
optional).
|
| voidĀ |
rb_cvar_set(VALUE class, ID name, VALUE val")
|
| Ā |
Setzt die Klassenvariable name in der Klasse
class auf value.
|
| VALUEĀ |
rb_cvar_get(VALUE class, ID name")
|
| Ā |
Liefert den Wert der Klassenvariablen name der Klasse class.
|
| intĀ |
rb_cvar_defined(VALUE class, ID name")
|
| Ā |
Liefert Qtrue wenn die Klassenvariable
name in class bereits definiert wurde; ansonsten liefert es
Qfalse.
|
| voidĀ |
rb_cv_set(VALUE class, const char *name, VALUE val")
|
| Ā |
Setzt die Klassenvariable namens name
(der mit einem ``@@''-Prefix beginnen muss) in der Klasse
class auf den Wert value.
|
| VALUEĀ |
rb_cv_get(VALUE class, const char *name")
|
| Ā |
Liefert den Wert der Klassenvariablen namens name
(der mit einem ``@@''-Prefix beginnen muss) der Klasse class.
|
| Status von Objekten |
|---|
| Ā |
OBJ_TAINT(VALUE obj")
|
| Ā |
Markiert das gegebene Objekt obj als tainted (verdorben).
|
| intĀ |
OBJ_TAINTED(VALUE obj")
|
| Ā |
Liefert etwas ungleich Null, wenn obj als tainted markiert ist.
|
| Ā |
OBJ_FREEZE(VALUE obj")
|
| Ā |
Markiert das Objekt obj als frozen (eingefroren/unveränderbar).
|
| intĀ |
OBJ_FROZEN(VALUE obj")
|
| Ā |
Liefert etwas ungleich Null, wenn obj als frozen markiert ist.
|
| Ā |
Check_SafeStr(VALUE str")
|
| Ā |
Wirft eine SecurityError-Ausnahme, wenn der derzeitige Sicherheitslevel > 0 und str
als tainted markiert ist, oder eine TypeError-Ausnahme, wenn str kein T_STRING ist.
|
| intĀ |
rb_safe_level(")
|
| Ā |
Liefert den momentanen Sicherheitslevel zurück.
|
| voidĀ |
rb_secure(int level")
|
| Ā |
Wirft eine SecurityError-Ausnahme, wenn level <= derzeitiger Sicherheitslevel.
|
| voidĀ |
rb_set_safe_level(int newlevel")
|
| Ā |
Setzt den derzeitigen Sicherheitslevel auf newlevel.
|
| Häufig eingesetzte Methoden |
|---|
| VALUEĀ |
rb_ary_new(")
|
| Ā |
Liefert ein neues Array der Defaultgröße.
|
| VALUEĀ |
rb_ary_new2(long length")
|
| Ā |
Liefert ein neues Array der angegebenen Länge length.
|
| VALUEĀ |
rb_ary_new3(long length, ...")
|
| Ā |
Liefert ein neues Array der angegebenen Länge length, das mit den
restlichen Argumenten bevölkert wird.
|
| VALUEĀ |
rb_ary_new4(long length, VALUE *values")
|
| Ā |
Liefert ein neues Array der angegebenen Länge length,
das mit den Werten des C-Feldes values besetzt wird.
|
| voidĀ |
rb_ary_store(VALUE self, long index, VALUE value")
|
| Ā |
Speichert den Wert value an die Indexposition index
des Feldes self.
|
| VALUEĀ |
rb_ary_push(VALUE self, VALUE value")
|
| Ā |
Hängt den Wert value ans Ende des Feldes self an. Liefert
value.
|
| VALUEĀ |
rb_ary_pop(VALUE self")
|
| Ā |
Entfernt und liefert das letzte Element des Feldes self.
|
| VALUEĀ |
rb_ary_shift(VALUE self")
|
| Ā |
Entfernt und liefert das erste Element des Feldes self.
|
| VALUEĀ |
rb_ary_unshift(VALUE self, VALUE value")
|
| Ā |
Hängt den Wert value am Beginn des Feldes self ein. Liefert
value.
|
| VALUEĀ |
rb_ary_entry(VALUE self, long index")
|
| Ā |
Liefert das index.te Elemente des Feldes self.
|
| intĀ |
rb_respond_to(VALUE self, ID method")
|
| Ā |
Liefert einen Wert ungleich Null, wenn self auf die Methode method antwortet.
|
| VALUEĀ |
rb_thread_create(VALUE (*func)(), void *data")
|
| Ā |
Startet die Funktion func in einem neuen Thread, wobei data als Argument
übergeben wird.
|
| VALUEĀ |
rb_hash_new(")
|
| Ā |
Liefert einen neuen, leeren Hash (assoziatives Feld).
|
| VALUEĀ |
rb_hash_aref(VALUE self, VALUE key")
|
| Ā |
Liefert das zum Schlüssel key in self gehörende Element.
|
| VALUEĀ |
rb_hash_aset(VALUE self, VALUE key, VALUE value")
|
| Ā |
Setzt in self den Wert des zum Schlüssel key gehörenden Elements
auf value. Liefert value.
|
| VALUEĀ |
rb_obj_is_instance_of(VALUE obj, VALUE klass")
|
| Ā |
Liefert Qtrue, falls obj eine Instanz der Klasse klass ist.
|
| VALUEĀ |
rb_obj_is_kind_of(VALUE obj, VALUE klass")
|
| Ā |
Liefert Qtrue, falls klass die Klasse oder eine der Oberklassen
von obj ist.
|
| VALUEĀ |
rb_str_new(const char *src, long length")
|
| Ā |
Liefert einen neuen String, der mit den length Zeichen
aus src initialisiert wird.
|
| VALUEĀ |
rb_str_new2(const char *src")
|
| Ā |
Liefert einen neuen String, der mit dem nullterminierten
C string src initialisiert wird.
|
| VALUEĀ |
rb_str_dup(VALUE str")
|
| Ā |
Liefert ein neues String Objekt, das eine Kopie von str enthält.
|
| VALUEĀ |
rb_str_cat(VALUE self, const char *src, long length")
|
| Ā |
Hängt die length Zeichen von src an den
Stringself an. Liefert self.
|
| VALUEĀ |
rb_str_concat(VALUE self, VALUE other")
|
| Ā |
Hängt other an
den Stringself an. Liefert self.
|
| VALUEĀ |
rb_str_split(VALUE self, const char *delim")
|
| Ā |
Liefert ein Feld von String-Objekten, die durch Auftrennen von
self an den Stellen delim entstehen. |
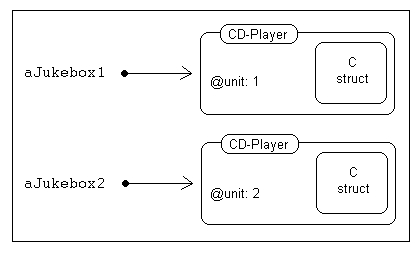 Figur 17.1 C-Datentypen in Objekte wrappen
Um an Rubys Mark-and-Sweep Garbage-Collection-Prozess teilzunehmen,
muss man eine Funktion definieren, die die Struktur wieder frei gibt und
möglicherweise auch eine Routine, die alle von ihr referenzierten anderen
Strukturen markiert (die dürfen dann nämlich nicht entsorgt werden, der Übersetzer).
Beide Routinen bekommen einen
Figur 17.1 C-Datentypen in Objekte wrappen
Um an Rubys Mark-and-Sweep Garbage-Collection-Prozess teilzunehmen,
muss man eine Funktion definieren, die die Struktur wieder frei gibt und
möglicherweise auch eine Routine, die alle von ihr referenzierten anderen
Strukturen markiert (die dürfen dann nämlich nicht entsorgt werden, der Übersetzer).
Beide Routinen bekommen einen 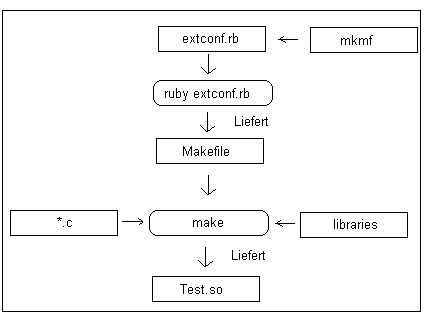 Figur 17.2 Eine Erweiterung erstellen
Figur 17.2 Eine Erweiterung erstellen